Куратор раздела

Авторские права
Авторские права на данный материал принадлежат Шустикову Владимиру Александровичу и Виндюкову Евгению Владиславовичу.
Размещение материала в открытых источниках допускается только в рамках цитирования с обязательным указанием источника.
Полное или частичное размещение данного материала на платных ресурсах, а также его коммерческое использование запрещено без письменного разрешения правообладателей.
AirFlow
Apache Airflow — это система, которая управляет выполнением задач по расписанию и в нужном порядке.
Представь, что у тебя есть много шагов:
сначала скачать данные → потом обработать → потом сохранить → потом отправить отчёт.
Airflow следит за тем, чтобы каждый шаг запускался вовремя и только после предыдущего.
Все шаги объединяются в схему, которая называется DAG — это план выполнения задач, где каждая задача знает, когда и после чего ей нужно запускаться.
Важно: Airflow сам не обрабатывает данные, а лишь организует и контролирует процессы, которые это делают.
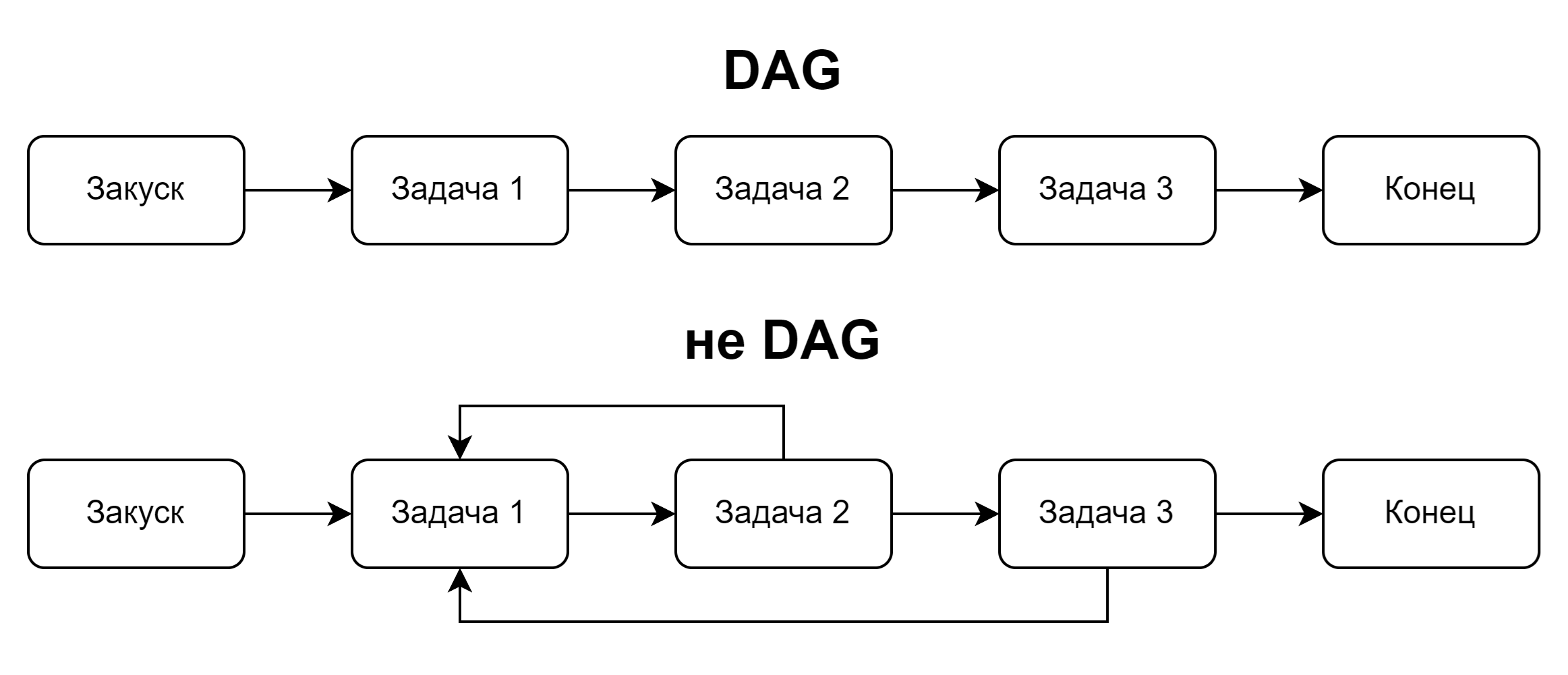
DAG
DAG (Directed Acyclic Graph — направленный ациклический граф) — это набор задач (tasks), которые выполняются в определённом порядке: последовательно или параллельно.
Главная особенность DAG — отсутствие циклов.
Это значит, что задачи не могут зависеть друг от друга по кругу: каждая задача выполняется только после своих зависимостей.
Архитектура AirFlow
AirFlow состоит из четырёх основных, взаимосвязанных компонентов:
- Планировщик AirFlow (Scheduler)
- Исполнитель (Executor)
- Воркеры (Workers)
- Веб-сервер AirFlow
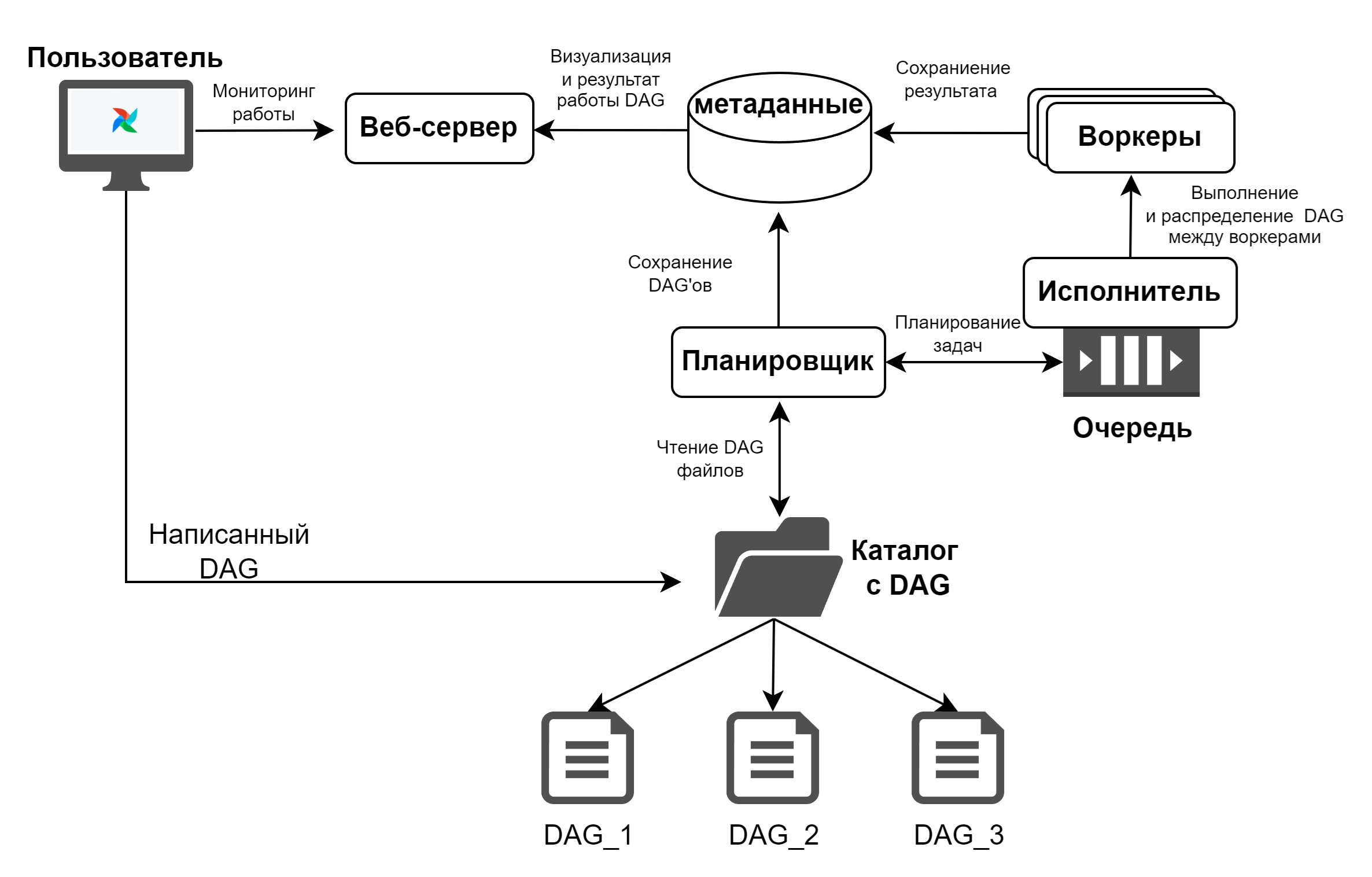
Задачи планировщика
- Анализ графа;
- Проверка параметра schedule_interval, который определяет частоту выполнения DAG;
- Планирование очереди графов.
Задачи Исполнителя
- Запуск задач;
- Распределение задач между воркерами.
Задачи воркеров
- Получает задачи от исполнителя;
- Отвечает за полное выполнение задач.
Задачи Веб-сервера AirFlow
- Визуализация DAG'а, который проанализировал планировщик;
- Предоставляет интерфейс пользователю для отслеживания работы DAG.
AirFlow UI(User Interface)
Перед тем как перейти к теме «Как писать код в Airflow», кратко познакомимся с интерфейсом (UI) Airflow.
Мы будем работать с версией Airflow 2.11.0.
Интерфейс Airflow — это веб-панель управления, в которой можно:
- просматривать DAG-и,
- запускать и останавливать пайплайны,
- анализировать выполнение задач,
- отслеживать ошибки и логи,
- управлять расписанием и настройками.
Разберём основные окна UI, которые понадобятся нам в работе.
После ввода логина и пароля (если они настроены) открывается главное окно Airflow.
Верхняя панель

В верхней панели находятся основные разделы:
DAGs — список всех DAG’ов (главная рабочая вкладка)
Cluster Activity — загрузка кластера, очереди, активные задачи
Datasets — датасеты и их зависимости
Security — пользователи, роли, права доступа
Browse — просмотр логов, задач, XCom, DagRuns
Admin — системные настройки Airflow
Docs — документация Airflow
В рамках обучения DE/DA хватит изучения только вкладок: DAGs, Browse и Admin.
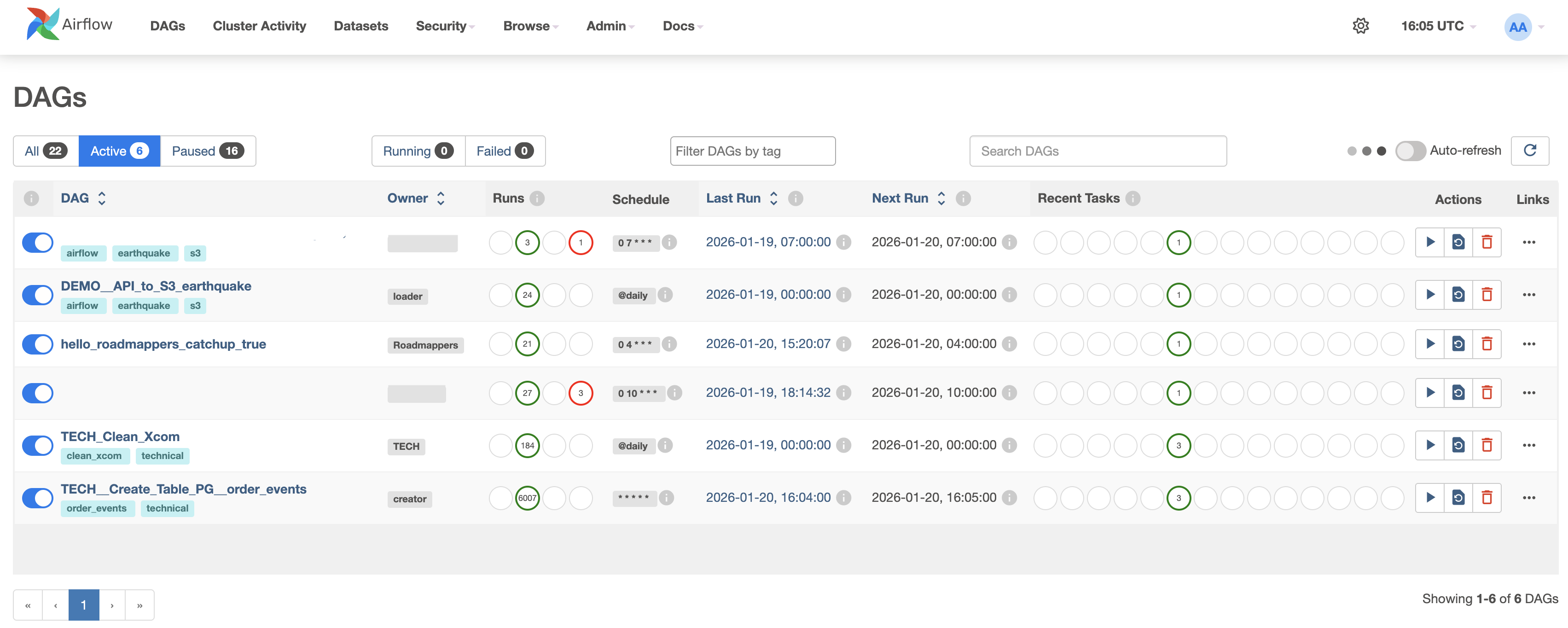
Фильтрация DAGs

В верхней части списка:
All — все DAG’и
Active — включённые (On)
Paused — выключенные (Off)
Running – Запущенные DAG'и
Failed - DAG'и, отработавшие с ошибкой
Filter DAGs by tag – фильтр DAG'a по тегу
Search DAGs – строка поиска DAG’а по всем полям
Таблица DAGs

Каждая строка — это один DAG. Дальше разберем структуру таблицы по колонкам:
DAG– Название DAG’а (параметрdag_id(далее в материале)). Если кликнуть по имени, откроется граф DAG’а. Под названием отображаются теги (airflow, s3, technical и т.д.) для простой фильтрации и объединения в логические группы. Переключатель слева: On(Синий) — DAG включён,Off(Серый)— DAG на паузе (не будет запускаться).Owner– Ответственный за DAG.Runs– История запусков DAG’а: В очереди, Успешные, Запущенные, Упавшие и их количество.Schedule– Расписание DAG’а. С какой периодичностью будет запускаться DAG. По этому полю сразу видно автоматический DAG или ручной.Last Run– Дата и время последнего логического запуска DAG’а. Логическая дата относительно запуска, используется для параметраcatchup(далее в материале).Next Run– Дата и время следующего запуска DAG’а. Если пусто, то DAG либо выключен, либоschedule=None.Recent Tasks– Состояние задач из последнего запуска. Это быстрый способ понять: «Что сейчас происходит внутри DAG’а»Actions– Основные действия с DAG’ом: Запуск, Обновление состояния, УдалениеLinks– Быстрые действия. Функционал кнопок из страницы самого DAG'а.
Информация о DAG'е
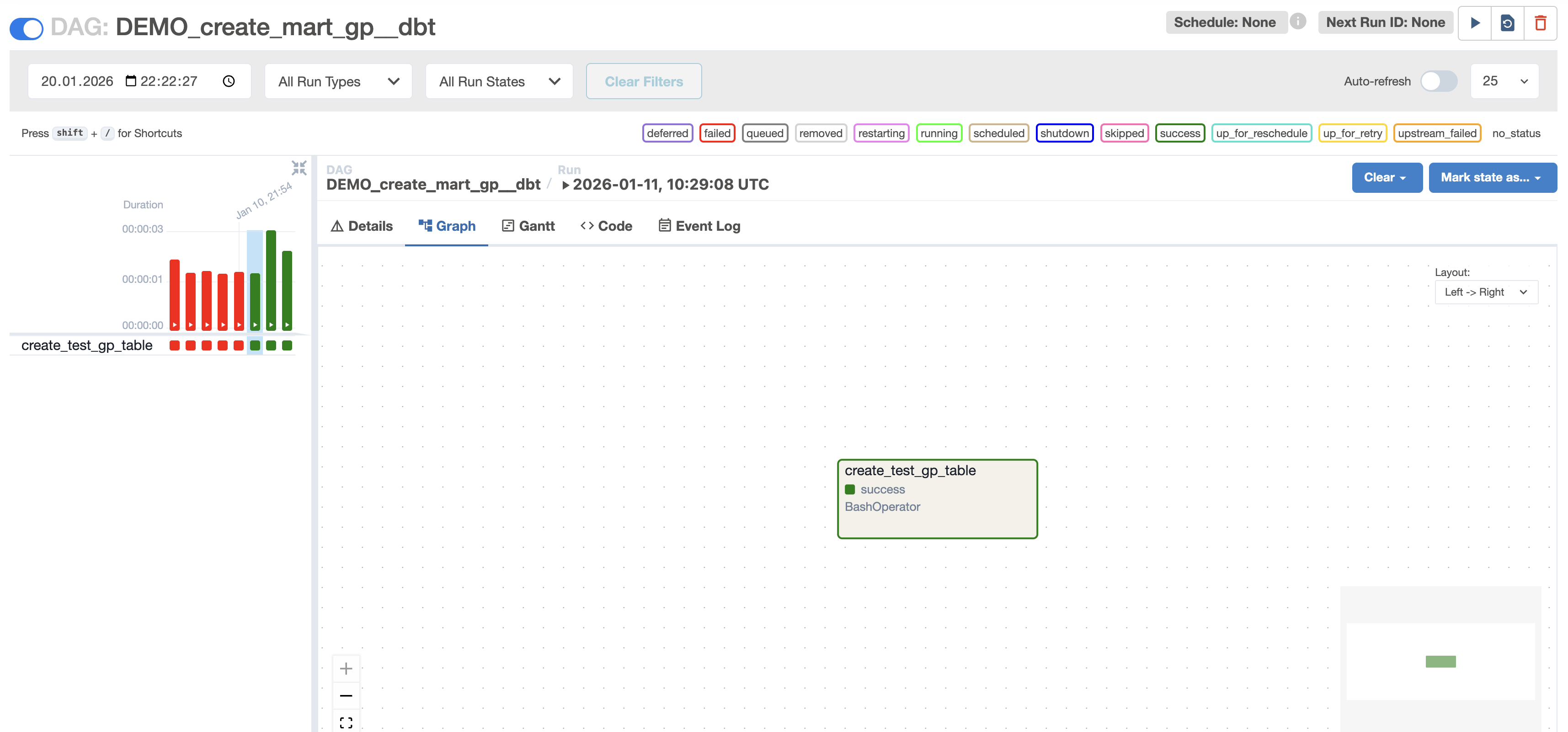
На данной странице располагается полноценная информация о ходе работы DAG'а.
Верхняя панель

Верхняя часть (слева направо):
- Вкл/Выкл DAG.
- Имя DAG’а.
- Расписание.
- Информация о следующем запуске DAG’а.
- Основные действия с DAG’ом.
Средняя часть:
- Фильтрация по дате и времени
- Фильтрация по типу запуска (scheduled — запуск по расписанию, manual — ручной запуск, backfill — догоняющий запуск (за пропущенные даты), dataset_triggered — запуск по обновлению датасета)
- Фильтрация по состоянию
- Автообновление
Нижняя часть:
- Легенда состояния задач в Airflow(таблица ниже)
| State | Значение | Краткое описание |
|---|---|---|
| success | Успешно | Задача успешно выполнена. |
| failed | Ошибка | Задача завершилась с ошибкой. |
| running | Выполняется | Задача выполняется прямо сейчас. |
| queued | В очереди | Задача стоит в очереди на выполнение. |
| scheduled | Запланирована | Задача запланирована, но ещё не поставлена в очередь. |
| up_for_retry | Повтор | Задача упала, но будет выполнена повторно. |
| up_for_reschedule | Отложена | Задача отложена и будет перепланирована. |
| skipped | Пропущена | Задача пропущена. |
| upstream_failed | Не запущена | Задача не запущена из-за ошибки upstream-задачи. |
| deferred | Ждёт событие | Задача отложена событием. |
| removed | Удалена | Задача была удалена из DAG’а. |
| shutdown | Остановлена | Задача была принудительно остановлена. |
Состояние задачи
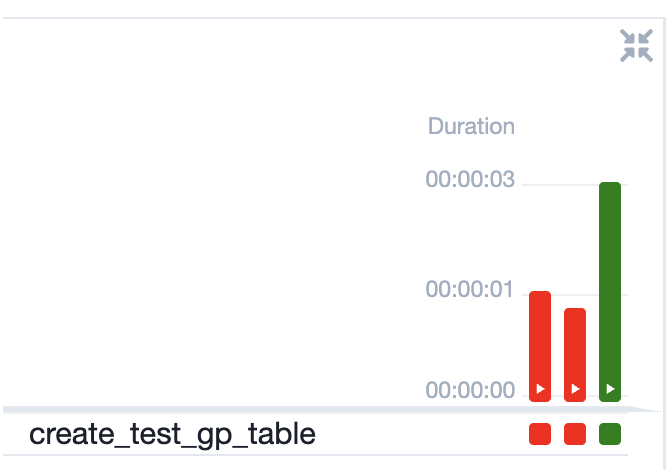
У состояний задач есть 3 цвета:
🟥 Красный — ошибка (failed)
🟩 Зелёный — успешно (success)
🟨 Жёлтый(Светло-зелёный) — выполняется (running)
Режимы просмотра

Details — информация о запуске DAG'а
Graph — граф задач и зависимостей (Сюда будете лазить в 95% случаев). По сути это визуальное представление DAG’а.
Gantt — временная диаграмма выполнения
Code — код DAG’а
Event Log — системные события Airflow
Если перейти во вкладку Graph и нажать на задачу(таску), то появятся дополнительные вкладки, относящиеся к данной таске.
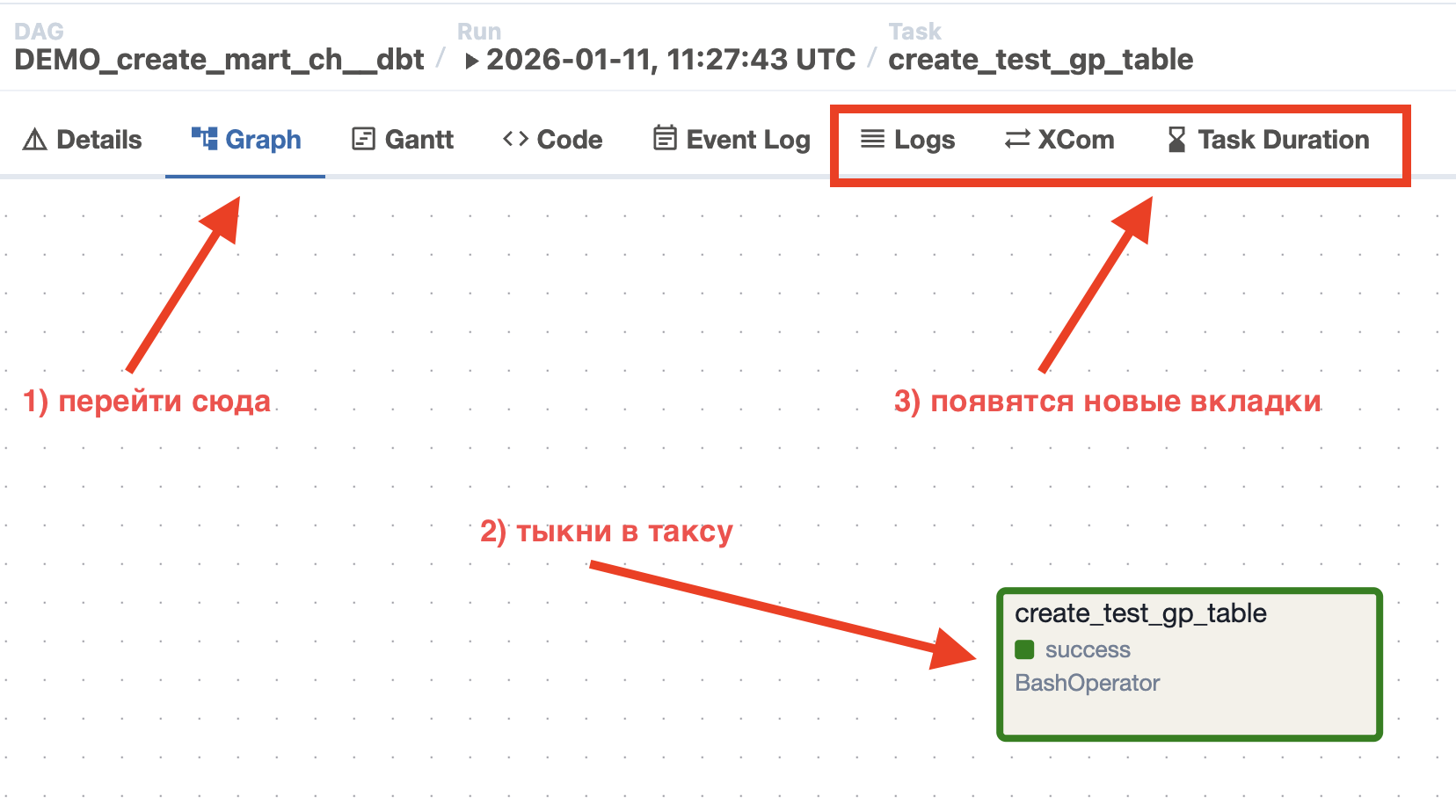
Logs — логи выполнения задачи
XCom — информация об XCom(Будет рассмотрено дальше)
Task Duration — детали выполнения
На этом знакомство с UI заканчиваем. Этих знаний с головой хватит для выполнения первых задач. Впереди мы подробно разберём Variables, Connections, XComs, поэтому изучай материал дальше и постепенно освоишь основные инструменты, с которыми столкнёшься на своём непростом пути! А дальше мы переходим к самому интересному — написанию кода самих DAG’ов.
DAG
Понятие DAG (Directed Acyclic Graph) – это основа всей работы с AirFlow. Как мы уже говорили, DAG — это ациклический граф задач, которые могут выполняться последовательно или параллельно. Самое главное правило: DAG не может быть цикличным.
Объявление DAG можно выполнять несколькими способами:
1 Способ:
Показать код
import airflow
dag = airflow.DAG(
dag_id = 'uniq_name',
## ПАРАМЕТРЫ
)
with dag:
task_1 = Operator(
## Параметры оператора
)
task_1Пример:
Показать код
import airflow
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
dag = airflow.DAG(
dag_id="first_dag_1",
start_date=days_ago(2),
schedule_interval=None,
tag='roadmappers'
)
with dag:
hello_rm = BashOperator(
task_id="hello_rm",
bash_command='echo "Hello Roadmappers.ru"'
)
hello_rm2 Способ:
Показать код
from airflow.operators.python import PythonOperator
dag = airflow.DAG(
dag_id = 'uniq_name',
## ПАРАМЕТРЫ
)
task_1 = Operator(
## Параметры оператора
dag=dag ## отношение к дагу передаётся в таске
)
task_1Пример:
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
dag = DAG(
dag_id="first_dag_2",
start_date=days_ago(2),
schedule_interval=None,
tag='roadmappers'
)
hello_rm = BashOperator(
task_id="hello_rm",
bash_command='echo "Hello Roadmappers.ru"',
dag=dag
)
hello_rm3 Способ:
Показать код
from airflow import DAG
with DAG(
dag_id = 'uniq_name',
## ПАРАМЕТРЫ
) as dag:
task_1 = Operator(
## Параметры оператора
)
task_1Пример:
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
with DAG(
dag_id="first_dag_3",
start_date=days_ago(2),
schedule_interval=None,
tag='roadmappers'
) as dag:
hello_rm = BashOperator(
task_id="hello_rm",
bash_command='echo "Hello Roadmappers.ru"'
)
hello_rmВыбор способа объявления DAG’а не влияет на работу и зависит исключительно от предпочтений разработчика или принятого в команде стандарта оформления кода.
Параметры DAG'а
Параметры DAG’а можно задавать двумя способами:
- Напрямую в конструкторе DAG – все параметры указываются при создании объекта DAG (кроме
dag_id, который обязателен). - Через
default_args– создаётся словарь с параметрами по умолчанию и передаётся в DAG через аргументdefault_args.
Чаще всего используют второй способ, потому что так проще поддерживать и менять настройки для нескольких DAG’ов одновременно. Мы будем использовать именно его.
В DAG можно передавать достаточно большое количество параметров (со всеми параметрами можно ознакомиться тут (opens in a new tab)).
Мы рассмотрим только основные, но это не означает, что все их нужно обязательно указывать в каждом DAG'е.
Основные параметры:
dag_id – имя DAG’а. Обязательно должно быть уникальным!
schedule_interval – с какой периодичностью запускать DAG. None – ручной запуск. Способы передачи: CRON, timedelta, встроенные макросы @daily.
Макросы:
| Макрос | Значение |
|---|---|
@once | Один и только один раз |
@hourly | Запуск один раз в час в начале часа |
@daily | Запуск один раз в день в полночь |
@weekly | Запуск один раз в неделю в полночь в воскресенье |
@monthly | Запуск один раз в месяц в полночь первого числа месяца |
@yearly | Запуск один раз в год в полночь 1 января |
description - описание DAG’а.
depends_on_past — по умолчанию False. Если установить True, текущий экземпляр задачи не будет выполняться, пока эта же задача (task_id) в предыдущем запуске DAG не завершится успешно.
retries — количество повторных попыток выполнения задачи, если задача завершилась ошибкой.
retry_delay — это пауза между повторными попытками выполнения задачи в Airflow. Принимает timedelta(from datetime import timedelta). Например: timedelta(minutes=10)
start_date — логическая точка во времени, начиная с которой Airflow начинает планировать и запускать DAG. Чаще всего используют метод days_ago(from airflow.utils.dates import days_ago)
end_date — логическая граница, после которой Airflow перестаёт создавать новые запуски DAG.
catchup — настройка, отвечающая за создание пропущенных запусков DAG за прошлые периоды, если начальная дата указана раньше текущего момента. Например, если start_date равна 2026-01-01, а сегодня 2026-01-20, то Airflow создаст DAG для каждого дня с 2026-01-01 по 2026-01-20. С этим нужно быть аккуратным, чтобы не натворить чего лишнего.
execution_timeout — максимальное время выполнения одной задачи.
owner — параметр, определяющий ответственного за задачу или DAG.
email — перечень адресов электронной почты, на которые могут отправляться уведомления.
email_on_failure — при значении True включает отправку уведомлений при ошибке выполнения задачи.
email_on_retry — при значении True включает уведомления при повторном запуске задачи после сбоя.
tags – тег для фильтрации DAG'ов в UI (User Interface)
Перед тем как приступить к написанию последовательных DAG-файлов, рассмотрим ещё один объект, без которого не обходится ни один DAG – это Operator.
Operators
Именно операторы позволяют нам выполнять определённые задачи и выстраивать полноценный DAG. В AirFlow внедрено и написано достаточно большое количество операторов.
Часто встречаемые:
- BashOperator - вызываются Bash-команды
- PythonOperator - вызываются Python-скрипты
Другие примеры:
- EmailOperator
- HttpOperator
- SQLExecuteQueryOperator
- DockerOperator
- HiveOperator
- S3FileTransformOperator
- PrestoToMySqlOperator
- SlackAPIOperator
- DBTRunOperator
BashOperator
Давайте создадим DAG, который будет выводить в командной строке: "Привет Roadmappers! Ты лучшее, что есть на просторах интернета!"
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
from datetime import datetime
default_args = {
'owner': 'Roadmappers',
'start_date': days_ago(1),
'retries': 1,
'catchup': False
}
dag = DAG(
dag_id="hello_roadmappers",
start_date=datetime(2026, 1,1),
schedule_interval=None,
tags=['roadmappers'],
default_args=default_args
)
hello_rm = BashOperator(
task_id="hello_rm",
bash_command='echo "Привет Roadmappers! Ты лучшее, что есть на просторах интернета!"',
dag=dag
)
hello_rmПосмотрим на оператор и его основные параметры:
BashOperator(
task_id="hello_rm",
bash_command='echo "Привет Roadmappers! Ты лучшее, что есть на просторах интернета!"',
dag=dag
)task_id – это уникальное имя таски, в одном DAG-файле оно должно быть уникальным.
bash_command – команда Bash, которую необходимо выполнить.
А теперь ненадолго вернёмся к теме параметров самого DAG'а.
Обращаю внимание на параметр start_date!
Он указан у меня и в классе DAG, и в словаре default_args,
но Airflow не конфликтует. Это связано с тем, что default_args – это аргументы по умолчанию,
а аргументы, указанные в классе DAG, – это реальные аргументы, с которыми запускается сам DAG.
Поэтому одинаковые параметры, описанные в классе DAG, всегда перекрывают значения из словаря.
В нашем случае DAG возьмёт стартовую дату с 01-01-2026.
Также обращаю внимание на параметр catchup!
В нашем словаре он указан как False. Это необходимо для того, чтобы наш DAG запустился только один раз. В противном случае DAG будет запущен для всех дат, начиная с 01-01-2026!
Также DAG выполнится один раз, если schedule_interval равен None, т.е. при ручном запуске.
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
from datetime import datetime
default_args = {
'owner': 'Roadmappers',
'start_date': days_ago(1),
'retries': 1,
}
dag = DAG(
dag_id="hello_roadmappers_catchup_true",
start_date=datetime(2026, 1,1),
schedule_interval="0 4 * * *",
tags=['roadmappers'],
default_args=default_args
)
hello_rm = BashOperator(
task_id="hello_rm",
bash_command='echo "Привет Roadmappers! Дата запуска {{ ds }}"',
dag=dag
)
hello_rmАнализируя скрипт, наверняка заметил конструкцию типа {{ ds }} – это специальная конструкция, её ещё называют Jinja (фреймворк (opens in a new tab) шаблонов на Python).
Jinja даёт приятную "магию" при работе с AirFlow, но это не более чем удобный бонус, а основной фреймворк AirFlow всё равно остаётся главным инструментом.
Давай рассмотрим пример работы следующего шаблона. Допустим, нам необходимо пройтись по циклу и в Bash-команду подставлять определённые значения.
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
from datetime import datetime
default_args = {
'owner': 'Roadmappers',
'start_date': days_ago(1),
'retries': 1,
}
with DAG(
dag_id="jinja_for_example",
schedule_interval=None,
tags=['roadmappers'],
default_args=default_args
) as dag:
process_tables = BashOperator(
task_id="process_tables",
bash_command="""
{% for table in ['users', 'orders', 'payments'] %}
echo "Обрабатываю {{ table }}"
{% endfor %}
"""
)
По итогу должно получиться:
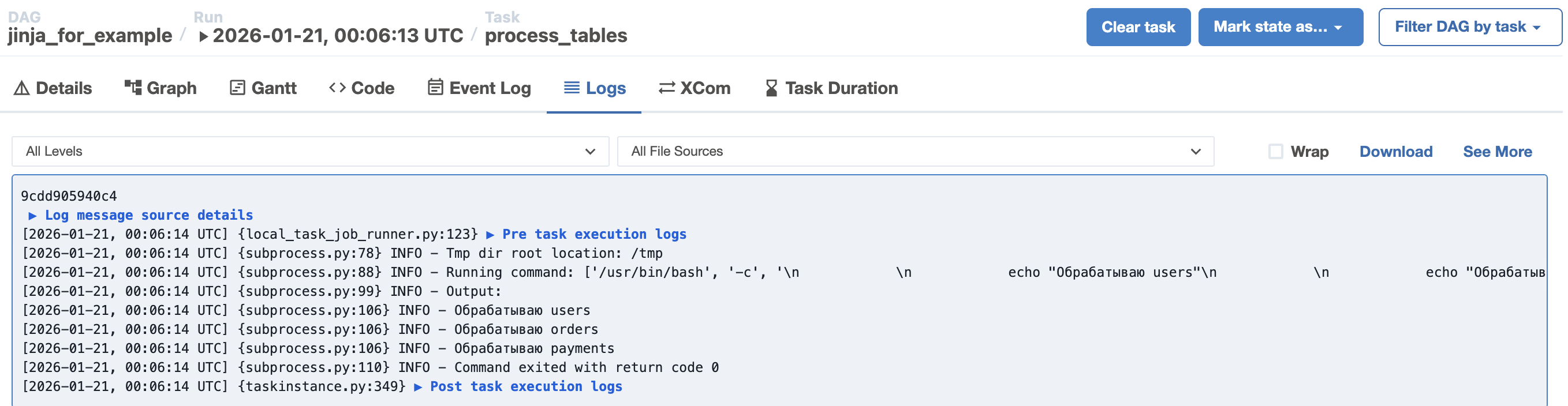
Скрипт, описанный в DAG'е:
{% for table in ['users', 'orders', 'payments'] %}
echo "Обрабатываю {{ table }}"
{% endfor %}для командной строки превращается в три последовательные друг за другом команды:
echo "Обрабатываю users"
echo "Обрабатываю orders"
echo "Обрабатываю payments"Где это может применяться? Например, при передаче параметра даты {{ ds }} для выкачивания данных из API за определённый день.
Существует достаточно много зарезервированных Jinja-шаблонов, встроенных в AirFlow, но их поиск и разбор остаётся на вашей ответственности.
В ходе обучения мы не раз ещё будем ссылаться на Jinja, так что особо волноваться не стоит — всё постепенно разберём.
PythonOperator
PythonOperator – основной инструмент в работе инженера данных или аналитика данных. Около 90% всех ETL/ELT (opens in a new tab) задач выполняются с его помощью.
Он позволяет запускать Python-функцию, как отдельную задачу DAG’а.
Показать код
from datetime import datetime
from airflow import DAG
from airflow.operators.python import PythonOperator
def hello_roadmappers():
print("Hello Roadmappers")
dag = DAG(
'hello_roadmappers',
description='Простой пример Hello Roadmappers DAG',
schedule_interval='@once',
start_date=datetime(2025, 6, 10),
tags=['roadmappers'],
catchup=False
)
hello_task = PythonOperator(
task_id='hello_task',
python_callable=hello_roadmappers,
dag=dag
)
hello_taskpython_callable — передаётся имя Python-функции, которую необходимо выполнить.
Довольно часто делают так, что операторы находятся в одном DAG-файле, а функции — в отдельном Python-файле, который затем просто импортируется.
Такой подход позволяет не захламлять основной DAG-файл и логически разделять функции по смысловым блокам. Например: один файл может содержать функции для обновления данных клиентов сервиса 1, другой — для сервиса 2.
Кастомный Operator
В AirFlow можно писать кастомные операторы, но это уже более продвинутый уровень. На начальных этапах изучения этого функционала можно не касаться.
Чтобы понимать, как писать свой оператор, необходимо знать, как работают классы и наследование в Python.
Если ты это знаешь, то на просторах интернета можно спокойно найти информацию о BaseOperator, от которого необходимо наследоваться для создания кастомного оператора.
Строим DAG из операторов. Последовательность задач.
Построить DAG не составляет никакого труда. Сам AirFlow позволяет задавать последовательность задач несколькими способами, но мы рассмотрим самый распространённый способ — с использованием операторов << и >> для задания зависимостей между тасками.
-
Task_1 >> Task_2– Task_1 выполняется перед Task_2. -
Task_2 << Task_3– Task_3 выполняется перед Task_2. -
Task_1 >> [Task_2, Task_3]– Task_2 и Task_3 запускаются одновременно после завершения Task_1. -
[Task_2, Task_3] >> Task_4– Task_2 и Task_3 выполняются одновременно, а после их завершения запускается Task_4.
Давайте рассмотрим работу DAG на примере и визуализируем последовательность задач с помощью пустых операторов (EmptyOperator).
EmptyOperator – это оператор, который ничего не делает, кроме того, что позволяет строить последовательность выполнения задач в DAG.
Показать код
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from datetime import datetime
with DAG(
dag_id="example_task_dependencies",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=['roadmappers'],
) as dag:
start = EmptyOperator(task_id="start")
step_1 = EmptyOperator(task_id="step_1")
step_2 = EmptyOperator(task_id="step_2")
parallel_1 = EmptyOperator(task_id="parallel_1")
parallel_2 = EmptyOperator(task_id="parallel_2")
parallel_3 = EmptyOperator(task_id="parallel_3")
join = EmptyOperator(task_id="join")
final_step_1 = EmptyOperator(task_id="final_step_1")
final_step_2 = EmptyOperator(task_id="final_step_2")
end = EmptyOperator(task_id="end")
separate_task = EmptyOperator(task_id="separate_task")
start >> step_1 >> step_2
step_2 >> [parallel_1, parallel_2, parallel_3]
[parallel_1, parallel_2, parallel_3] >> join
join >> final_step_1 >> final_step_2 >> end
separate_taskПосле добавления данного скрипта в AirFlow, можно увидеть следующую картину:
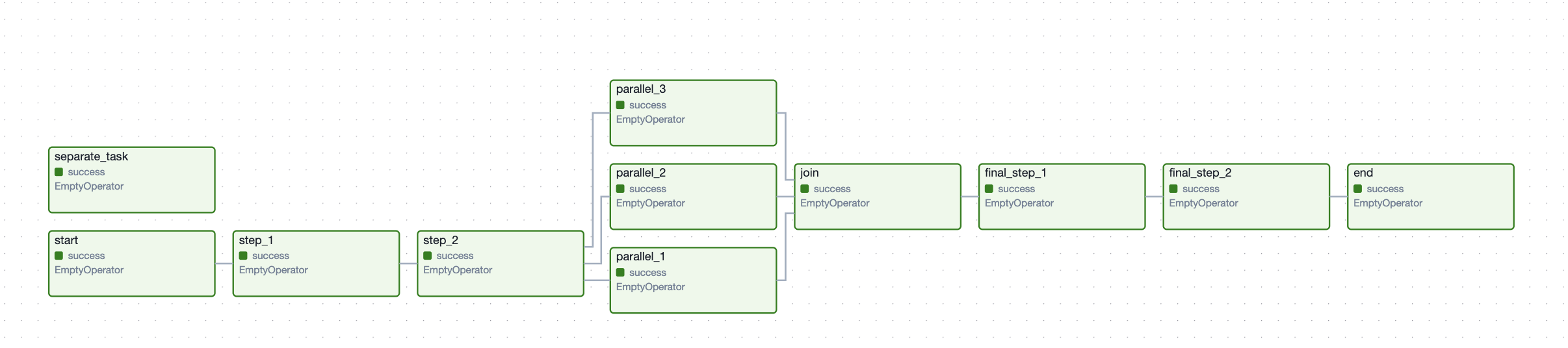
Обратите внимание на таску separate_task. Поскольку она не связана ни с одной другой задачей, она выполняется параллельно с таской start и независимо от падения других задач в DAG она завершится успешно, если пользователь явно не прервёт её выполнение.
Возможно, анализируя DAG, вы задавались вопросом: зачем нужен EmptyOperator, если он ничего не делает? На самом деле у него есть важное назначение – группировка задач. В нашем DAG это реализовано через таски start и end, которые объединяют последовательности задач в логические блоки.
Группировка тасок (TaskGroup)
Мы вскользь упомянули группировку и разграничение задач с помощью EmptyOperator, но это далеко не единственный способ.
В AirFlow существует TaskGroup. TaskGroup — это логическая группировка задач внутри DAG. Она объединяет несколько тасок в один визуальный блок, при этом не изменяя логику их выполнения.
Взяв предыдущий пример, разобьем задачу на 3 блока:
- step_1, step_2
- parallel_1, parallel_2, parallel_3, join
- final_step_1, final_step_2
- separate_task пусть будет отдельно задачей
При этом каждый подблок должен начинаться со start и заканчиваться end.
Показать код
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.utils.task_group import TaskGroup
from datetime import datetime
with DAG(
dag_id="taskgroup_example",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=['roadmappers'],
) as dag:
with TaskGroup("extract") as extract:
start = EmptyOperator(task_id="start")
step_1 = EmptyOperator(task_id="step_1")
step_2 = EmptyOperator(task_id="step_2")
end = EmptyOperator(task_id="end")
start>> step_1 >> step_2 >> end
with TaskGroup("transform") as transform:
start = EmptyOperator(task_id="start")
parallel_1 = EmptyOperator(task_id="parallel_1")
parallel_2 = EmptyOperator(task_id="parallel_2")
parallel_3 = EmptyOperator(task_id="parallel_3")
join = EmptyOperator(task_id="join")
end = EmptyOperator(task_id="end")
start >> [parallel_1, parallel_2, parallel_3] >> join>> end
with TaskGroup("load") as load:
start = EmptyOperator(task_id="start")
final_step_1 = EmptyOperator(task_id="final_step_1")
final_step_2 = EmptyOperator(task_id="final_step_2")
end = EmptyOperator(task_id="end")
start>> final_step_1 >> final_step_2 >> end
separate_task = EmptyOperator(task_id="separate_task")
extract >> transform >> load
separate_taskПосле загрузки получается:
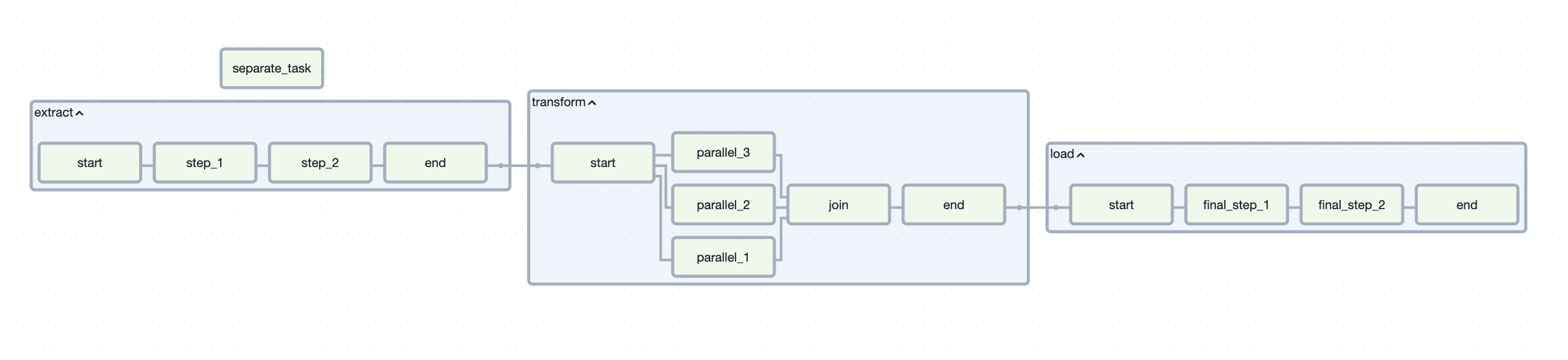
Если вдруг не заметили, я специально назвал подгруппы так, чтобы показать пример: первые два шага извлекают данные из источников, параллельные шаги их трансформируют и объединяют, а дальше данные загружаются в наши базы.
Это лишь модель, демонстрирующая возможности AirFlow, даже если цель — просто “навести красоту” визуально.
При этом TaskGroup поддерживает вложенность — можно группировать задачи внутри других групп, а не только на уровне DAG.
До этого момента мы рассматривали AirFlow как обычный фреймворк: положил задачу — и она выполняется в назначенное время. Это стандартная практика в большинстве компаний, использующих AirFlow.
Дальше мы углубимся в уникальные возможности AirFlow, заглянем в те места, куда обычно не заглядывают 90% разработчиков, пишущих DAG’и.
При этом время от времени мы будем возвращаться к базовым темам и полезным лайфхакам!
Первая полноценная задача
Бизнес-задача: первичная выгрузка и контроль данных из внешнего API.
Представим себе: компания использует внешний сервис (партнёрский или публичный), который предоставляет данные через REST API. Эти данные в дальнейшем:
- используются аналитиками,
- загружаются в DWH,
- участвуют в отчётности и витринах.
Перед тем как данные попадут в хранилище, необходимо посмотреть что за данные, провести небольшую валидацию этих данных.
Необходимо разработать DAG в Airflow, который:
- Регулярно выгружает данные из внешнего API(
https://jsonplaceholder.typicode.com/) - Сохраняет «сырые» данные в файловом виде в каталог
/tmp/roadmappers/... - Выполняет первичную проверку объёма данных (подсчитываем количество файлов и количество строк в них; должно выполняться параллельно для каждого файла).
Небольшие условности на данном этапе:
- У нас будет строго два файла
- Напишем две задачи, которые будут считать количество строк в своих файлах (data_part_1, data_part_2)
- Максимальное количество строк в файле равно 60
- Если файлы с таким именем существуют, то их перезаписываем
- API даёт выгрузить одновременно 100 строк по умолчанию
Для нашей первой полноценной задачи такое условие подходит идеально!
Если напишете код самостоятельно — будет очень круто.
Если нет — ниже представлен ход моего решения.
Первое, с чего мы начинаем, это выгрузка данных из API и сохранение данных в файлы.
- В файле объявим две константные переменные
DATA_DIR = "/tmp/roadmappers/api_data"
URL = "https://jsonplaceholder.typicode.com/posts"- Запрашиваем данные из API, преобразуем выгруженные данные в JSON, делим данные на блоки по 60 строк и сохраняем их в каталог, предварительно создав его. Весь код оборачиваем в функцию.
Ниже представлен код с пояснениями к каждой строчке.
!ВАЖНО! Вы видите код с комментариями, объясняющими происходящее. Не нужно заучивать каждый шаг, метод или функцию. При необходимости вы всегда можете загуглить нужный метод или функцию. Со временем часто используемые функции и методы будут запоминаться автоматически и работать на "машинальном уровне".
import requests
import json
import os
import math
def extract_and_split():
response = requests.get(URL) ## Считываем данные из файла
data = response.json() ## Переводим данные в формат JSON
os.makedirs(DATA_DIR, exist_ok=True) ## Создаем каталог /tmp/roadmappers/api_data
chunk_size = 60 ## объявляем количество строк в одном блоке (чанке) данных
total_rows = len(data) ## У нас JSON формата [{...},{...},{...}] получаем количество {...} оно по умолчанию равно 100
total_files = total_rows // chunk_size ## получаем количество файлов при целочисленном делении 100//60 = 2
for i in range(total_files): ## проходимся дважды по циклу. Не забываем, что range начинает счёт с нуля
chunk = data[i * chunk_size:(i + 1) * chunk_size] ## берем определенный кусок данных
file_path = f"{DATA_DIR}/data_part_{i + 1}.json" ## формируем каталог
with open(file_path, "w", encoding="utf-8") as f: ## создаем файл и записываем в него данные
json.dump(chunk, f, ensure_ascii=False) ## сериализуем наш JSON
print(f"Создан файл {file_path}") ## логируем информацию о сохранении файлаОператор в DAG’е будет вызваться следующим образом:
extract_api = PythonOperator(
task_id="extract_and_split",
python_callable=extract_and_split
)- Пишем функцию, которая подсчитывает количество строк данных в файле.
С учетом наших условностей мы знаем, что у нас есть два файла: data_part_1 и data_part_2. Нам необходимо создать 2 параллельные таски, которые будут подсчитывать количество строк в каждом файле.
Писать две одинаковые функции с разницей только в имени файла для каждой таски — нерационально. В параметр python_callable передаётся исключительно имя функции без аргументов. Но как же передать аргументы?
Разработчики PythonOperator позаботились об этом с помощью двух параметров:
op_args— передача списка позиционных аргументовop_kwargs— передача словаря именованных аргументов
Проще говоря, это обычные args и kwargs Python.
Для примера в одной таске мы будем использовать op_args, а в другой — op_kwargs.
def count_rows(file_name): ## Объявляем функции с одним параметром имени файла
file_path = f"{DATA_DIR}/{file_name}" ## формируем строку
with open(file_path, "r", encoding="utf-8") as f: ## открываем наш файл на чтение
data = json.load(f) ## считываем JSON, хранящийся внутри файла
print(f"Файл {file_name}: {len(data)} строк") ## Выводим информацию о кол-ве строкОператоры объявляем следующим образом:
count_rows_1 = PythonOperator(
task_id="count_rows_file_1",
python_callable=count_rows,
op_args=["data_part_1.json"]
)
count_rows_2 = PythonOperator(
task_id="count_rows_file_2",
python_callable=count_rows,
op_kwargs={"file_name":"data_part_2.json"}
)- И наконец, выполняем задачу по подсчёту количества файлов в каталоге.
В данном случае удобно использовать BashOperator. Код будет следующим:
count_files = BashOperator(
task_id="count_files",
bash_command=f"ls -1 {DATA_DIR} | wc -l" ## каталог передаем через f-строку
)По итогу получается следующий DAG:
Показать код
"""
## **First real task Roadmappers**
Этот DAG:
- выгружает данные из API
- сохраняет их в файлы
- параллельно считает количество файлов и количество строк в этих файлах
Используется как учебный пример.
"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.operators.empty import EmptyOperator
from datetime import datetime
import requests
import json
import os
DATA_DIR = "/tmp/api_data"
URL = "https://jsonplaceholder.typicode.com/posts"
def extract_and_split():
response = requests.get(URL)
data = response.json()
os.makedirs(DATA_DIR, exist_ok=True)
chunk_size = 60
total_rows = len(data)
total_files = total_rows // chunk_size
for i in range(total_files):
chunk = data[i * chunk_size:(i + 1) * chunk_size]
file_path = f"{DATA_DIR}/data_part_{i + 1}.json"
with open(file_path, "w", encoding="utf-8") as f:
json.dump(chunk, f, ensure_ascii=False, indent=2)
print(f"Создан файл {file_path} с {len(chunk)} строками")
def count_rows(file_name):
file_path = f"{DATA_DIR}/{file_name}"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
print(f"Файл {file_name}: {len(data)} строк")
with DAG(
dag_id="first_task_roadmappers",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"]
) as dag:
dag.doc_md = __doc__
start = EmptyOperator(task_id="start")
extract_api = PythonOperator(
task_id="extract_and_split",
python_callable=extract_and_split
)
count_files = BashOperator(
task_id="count_files",
bash_command=f"ls -1 {DATA_DIR} | wc -l"
)
count_rows_1 = PythonOperator(
task_id="count_rows_file_1",
python_callable=count_rows,
op_args=["data_part_1.json"]
)
count_rows_2 = PythonOperator(
task_id="count_rows_file_2",
python_callable=count_rows,
op_kwargs={"file_name":"data_part_2.json"}
)
end = EmptyOperator(task_id="end")
start >> extract_api
extract_api >> [count_files, count_rows_1, count_rows_2] >> end
Обрати внимание, в самом начале файла находится строка с описанием задания. Конечно, это сделано не просто так — таким образом показывается один из способов документирования DAG'а.
Всегда приятно открыть DAG в UI и сразу видеть, что в нём происходит.
В Python подобное называют docstring — «строкой документации». Её можно добавить к модулю, функции, классу и т.д., и её будет видно при наведении на какой-либо модуль, функцию и т.д. Например:
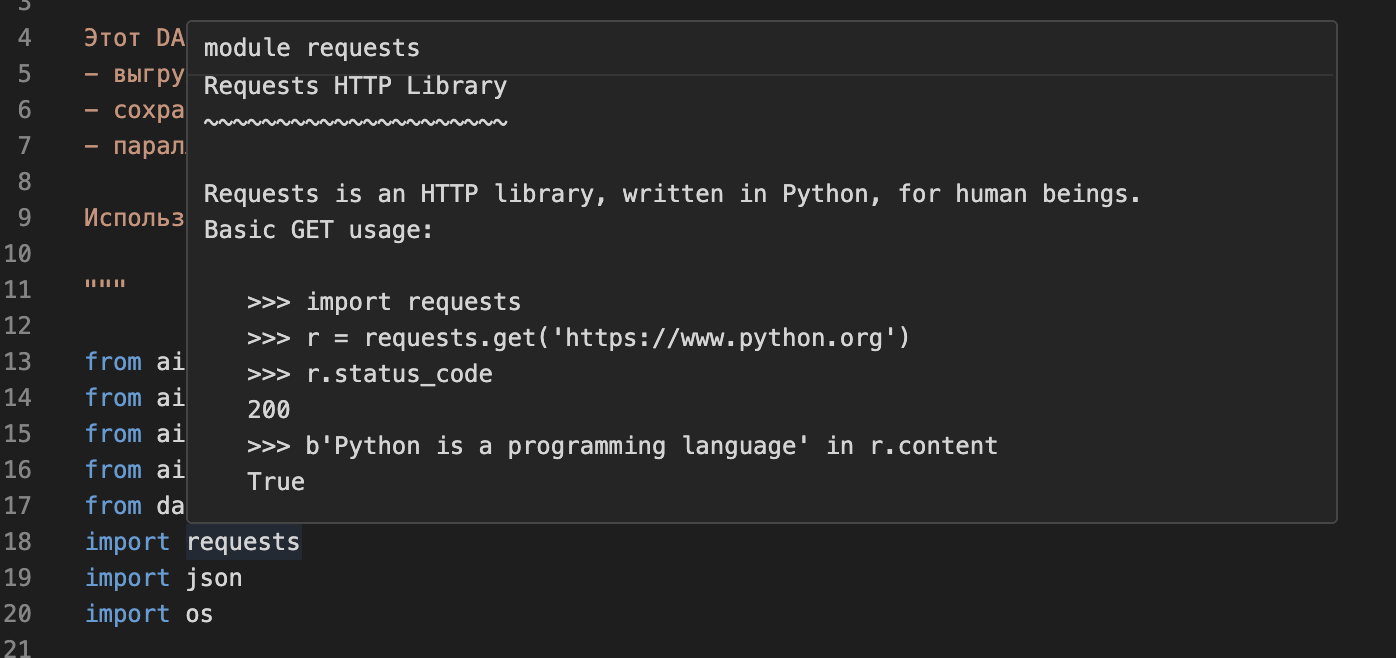
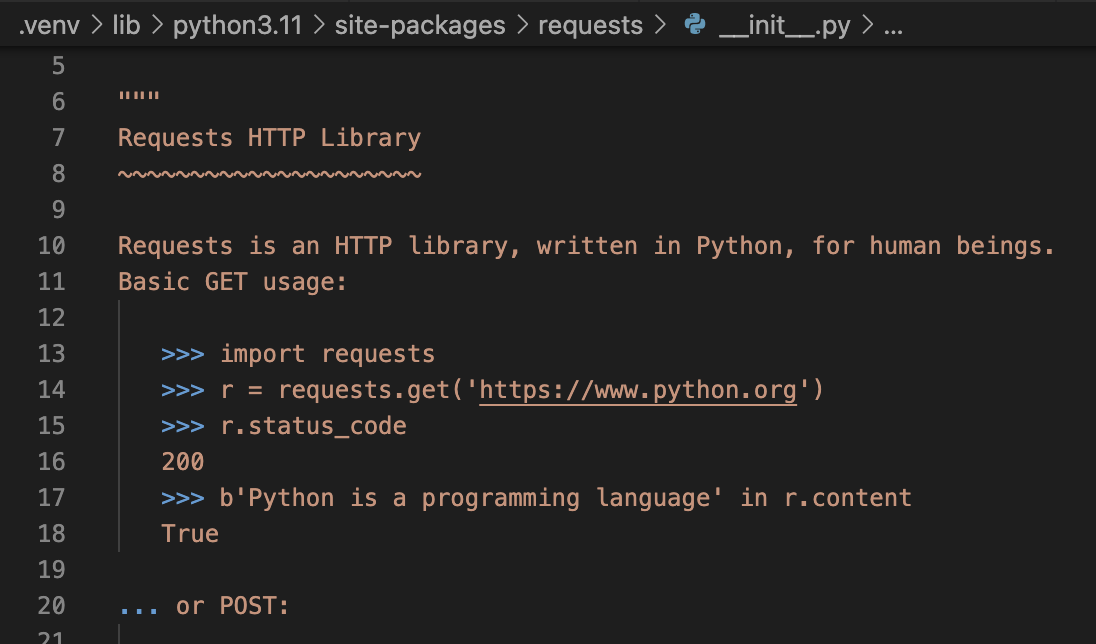
Если перейти в сам модуль requests, мы увидим строку с подобным текстом:
Не вдаваясь в подробности, мы можем передать эту строку в сам DAG с помощью строки:
dag.doc_md = __doc__dag.doc_md по умолчанию равен None, из-за чего окно с документацией в UI скрыто.
Параметр dag.doc_md принимает на вход строку, которая будет отображаться как документация DAG’а.
По сути, нам ничто не мешало написать:
dag.doc_md = """
## **First real task Roadmappers**
Этот DAG:
- выгружает данные из API
- сохраняет их в файлы
- параллельно считает количество файлов и количество строк в этих файлах
Используется как учебный пример.
"""Просто так делать не принято. Строка в начале файла или объекта попадает в специальную переменную __doc__. Если не веришь, можно выполнить примерный код ниже, чтобы убедиться. Именно эту строку рекомендуется передавать в dag.doc_md.
"""
Пример работы docstring. Ну что поверил?
"""
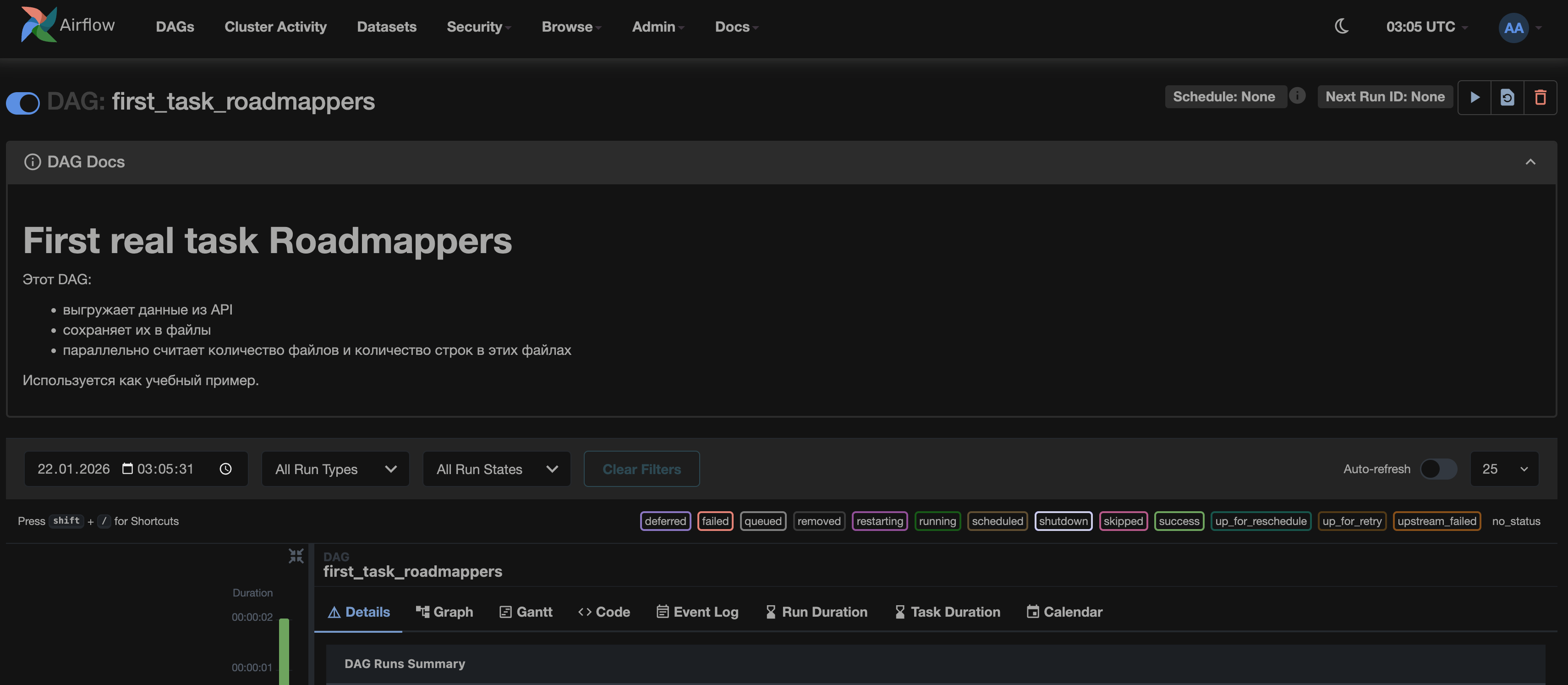
print(__doc__)Сама документация выглядит так(DAG Docs):
Теперь вернёмся к результату.
Посмотри на получившийся DAG.
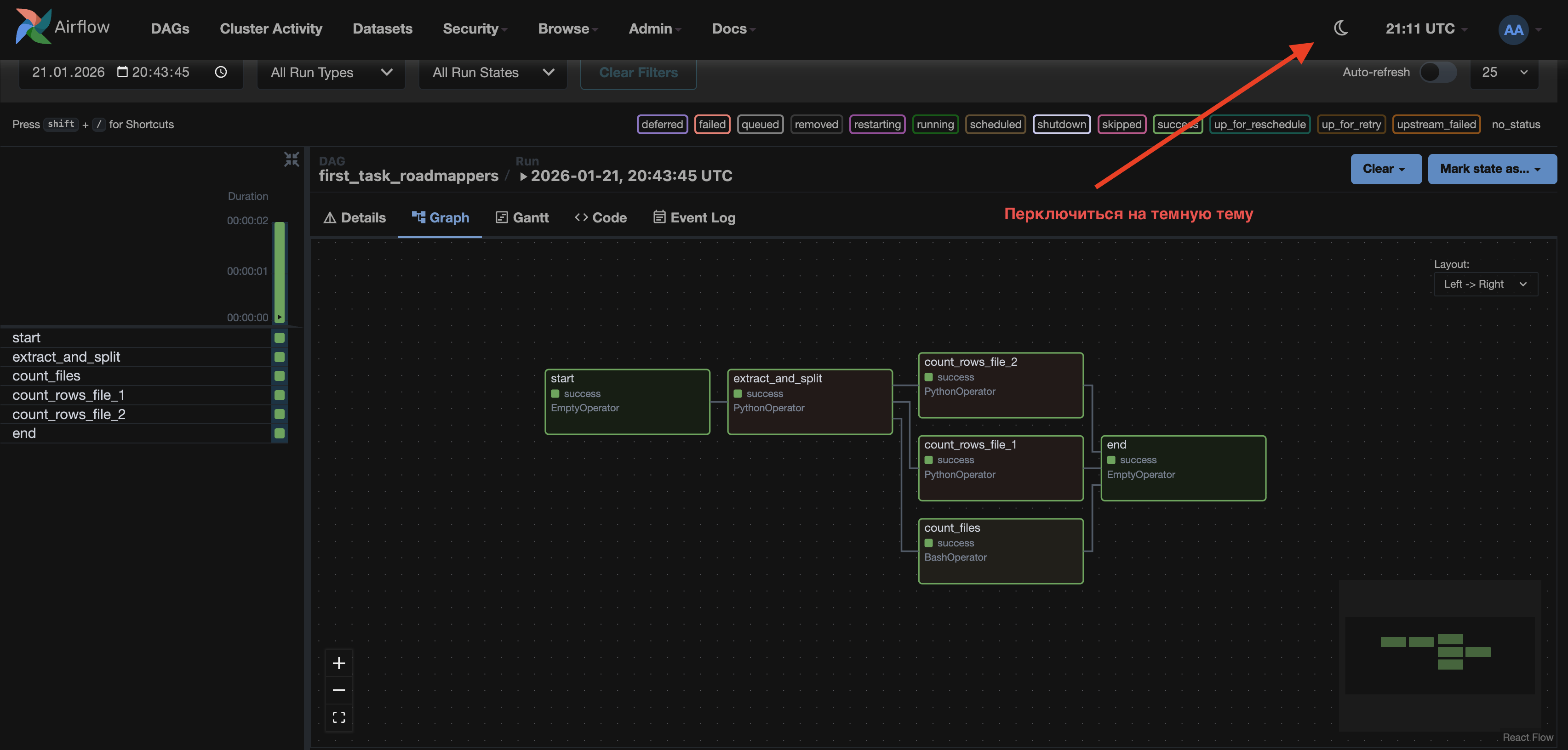
Самостоятельно зайди в лог тасок count_files, count_rows_1, count_rows_2 и посмотри на результаты.
Variable
На текущий момент мы уже умеем:
- писать DAG’и
- объявлять таски
- управлять зависимостями тасок
- передавать аргументы функций через оператор
Но есть одна ОГРОМНЕЙШАЯ проблема!
Мы всё хардкодим прямо в DAG-файле, что делает его малоуниверсальным и сложно поддерживаемым.
Примеры плохого кода:
- Пути к файлам
- Имена таблиц
- Даты
- URL API
Например, в прошлом задании мы захардкодили URL-адрес и рабочий каталог, куда сохраняли файлы.
DATA_DIR = "/tmp/api_data"
URL = "https://jsonplaceholder.typicode.com/posts"Зачастую хардкод (константы) затрудняет сопровождение кода. Если изменился какой-либо параметр, приходится лезть в DAG и править сам код.
Именно для решения этой проблемы в AirFlow существуют Variables — специальный инструмент для хранения параметров и настроек вне кода DAG’а.
Смысл максимально прост. Variables — это глобальные переменные AirFlow, которые:
- хранятся в базе AirFlow
- управляются через UI
- доступны из любого DAG’а
- позволяют отделить логику от конфигурации
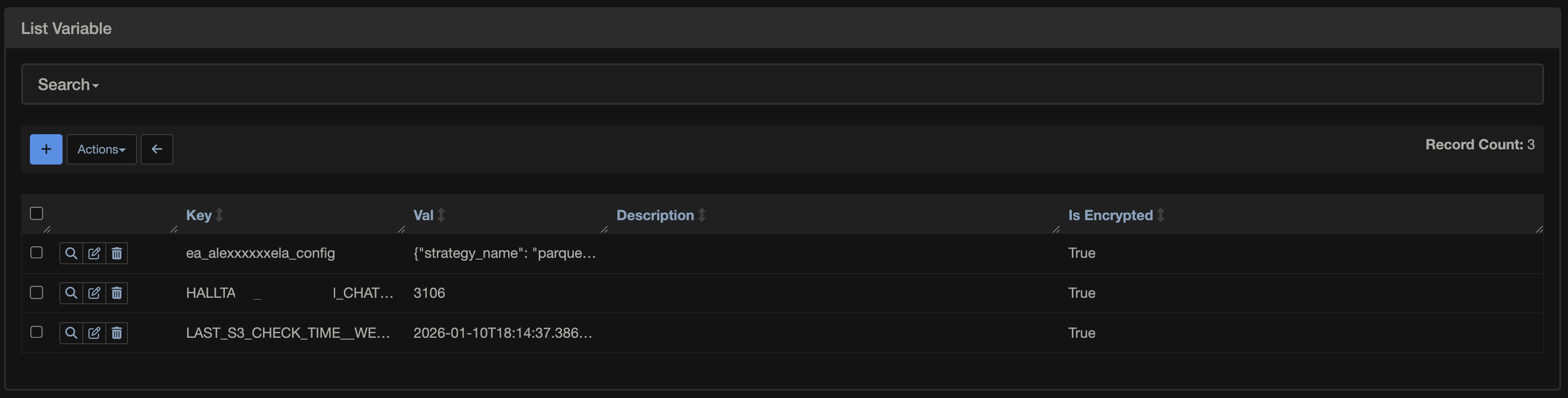
В UI AirFlow находятся по пути: Admin -> Variables
Каждая Variables состоит из:
- Ключа
- Значения
Также можно добавить комментарий и зашифровать значение.
Ну а теперь сразу к практике.
За основу возьмем предыдущую задачу, разместив каталог и URL в Variables. Также расчет количества файлов вынесем сразу после записи, а подсчет количества строк объединим в единую TaskGroup.
Получается DAG-файл следующего вида:
Показать код
"""
## **First real task Roadmappers**
Этот DAG:
- выгружает данные из API
- сохраняет их в файлы
- параллельно считает количество файлов и количество строк в этих файлах
Используется как учебный пример.
"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from airflow.operators.empty import EmptyOperator
from airflow.utils.task_group import TaskGroup
from airflow.models import Variable
from datetime import datetime
import requests
import json
import os
DATA_DIR = Variable.get("DATA_DIR")
URL = Variable.get("URL")
def extract_and_split():
response = requests.get(URL)
data = response.json()
os.makedirs(DATA_DIR, exist_ok=True)
chunk_size = 60
total_rows = len(data)
total_files = total_rows // chunk_size
for i in range(total_files):
chunk = data[i * chunk_size:(i + 1) * chunk_size]
file_path = f"{DATA_DIR}/data_part_{i + 1}.json"
with open(file_path, "w", encoding="utf-8") as f:
json.dump(chunk, f, ensure_ascii=False, indent=2)
print(f"Создан файл {file_path} с {len(chunk)} строками")
def count_rows(file_name):
file_path = f"{DATA_DIR}/{file_name}"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
print(f"Файл {file_name}: {len(data)} строк")
with DAG(
dag_id="first_task_roadmappers_var",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"]
) as dag:
dag.doc_md = __doc__
start = EmptyOperator(task_id="start")
extract_api = PythonOperator(
task_id="extract_and_split",
python_callable=extract_and_split
)
count_files = BashOperator(
task_id="count_files",
bash_command='ls -1 "{{ var.value.DATA_DIR }}" | wc -l'
)
with TaskGroup("count_rows") as count_rows_tg:
count_rows_1 = PythonOperator(
task_id="count_rows_file_1",
python_callable=count_rows,
op_args=["data_part_1.json"]
)
count_rows_2 = PythonOperator(
task_id="count_rows_file_2",
python_callable=count_rows,
op_kwargs={"file_name":"data_part_2.json"}
)
count_rows_1 >> count_rows_2
end = EmptyOperator(task_id="end")
(
start
>> extract_api
>> count_files
>> count_rows_tg
>> end
)Чтобы пользоваться Variable, необходимо выполнить импорт.
from airflow.models import VariableВ Python получить значение из Variable достаточно просто с помощью метода Variable.get(<имя_переменной>).
В нашем случае:
DATA_DIR = Variable.get("DATA_DIR")
URL = Variable.get("URL")Если есть необходимость получить значение из Variable, например, в BashOperator, то необходимо воспользоваться Jinja-шаблонами и в строку bash_command передать:
"{{ var.value.<имя_переменной> }}"count_files = BashOperator(
task_id="count_files",
bash_command='ls -1 "{{ var.value.DATA_DIR }}" | wc -l'
)Обрати внимание на способ задания зависимостей в этом примере.
(
start
>> extract_api
>> count_files
>> count_rows_tg
>> end
)В больших DAG’ах бывает сложно передавать длинные цепочки зависимостей, особенно если использовать одну строку с операторами >> или <<. Длинная строка становится нечитаемой и нарушает PEP8 (не более 79–80 символов на строку). Чтобы сделать код аккуратным и читаемым, длинные цепочки зависимостей можно обернуть в скобки () — Python будет воспринимать это как единую строку.
Connection
Вот мы дошли до одной из самых значимых и ключевых точек изучения AirFlow – Connections.
В реальных пайплайнах Airflow почти никогда не работает в вакууме. Он постоянно общается с различными источниками, будь то:
- Базы данных (PostgreSQL, ClickHouse, MySQL)
- API сервисы
- S3 / MinIO
- Kafka
- FTP / SFTP
- облака и BI-инструменты
И в большинстве случаев для этого нужны:
- хост
- порт
- логин
- пароль
- токены
Плохой практикой является ХАРДКОДИТЬ всё подряд:
conn = psycopg2.connect(
host="localhost",
user="admin",
password="admin123"
)В реальности все прекрасно понимают, что полностью избавиться от хардкода невозможно. Но безопасность всегда должна быть в приоритете, поэтому учётные данные (credentials) для подключений необходимо скрывать — как минимум в переменные среды.
Вы даже не представляете, сколько раз люди выкладывали в GitHub доступы к продакшн-базам данных. А потом приходилось срочно пересоздавать пароли, роли, ключи и права доступа — это долго, больно и опасно для бизнеса.(Шуст один из этих барашков)
С другой стороны, может возникнуть вопрос: а почему учётные данные (credentials) нельзя положить в Variables?
Дело в том, что Variables в AirFlow в большинстве случаев не предназначены для хранения секретов:
- У них нет структуры, которая позволяла бы группировать параметры одного подключения.
- Значения легко могут утечь в логи, так как Variables открыты в DAG и Jinja-шаблонах.
- В целом сложно отследить, какие параметры относятся к какому соединению.
Поэтому для безопасного хранения учётных данных существуют Connections.
Connection – это набор связанных параметров для подключения к внешним системам. Airflow возьмёт на себя:
- безопасное хранение
- стандартизацию
- удобный доступ из кода
Самое главное, что нужно понять в Connection.
DAG знает только conn_id, всё остальное — ответственность Airflow
Ну что, когда мы с теорией покончили, предлагаю перейти к практике и "попинать" пару простых примеров. Сейчас посмотрим, как с помощью AirFlow можно получать данные из различных источников.
HTTP API
Создаём Connection в UI:
Conn Id: api_jsonplaceholderConn Type: HTTPHost: https://jsonplaceholder.typicode.com (opens in a new tab)Extra:json{ "timeout": 10 }
Посмотри и выполни код
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.hooks.base import BaseHook
from datetime import datetime
import requests
def extract_one_record():
conn = BaseHook.get_connection("api_jsonplaceholder") ## Получаем connection по conn_id
print('посмотри сюда ->', conn.host, conn.login, conn.password, conn.extra)
base_url = conn.host ## Берём значение хоста
response = requests.get(f"{base_url}/posts") ## Подставляем значение хоста
data = response.json()
print("🔥 Первая запись из API:")
print(data[0]) ## Выводим первую запись
with DAG(
dag_id="http_api_BaseHook",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"]
) as dag:
extract_task = PythonOperator(
task_id="extract_one_record",
python_callable=extract_one_record
)
extract_taskВ DAG’е обратим внимание на несколько ключевых строк, а особенно на использование Hook:
from airflow.hooks.base import BaseHook
conn = BaseHook.get_connection("api_jsonplaceholder") ## Тут мы получаем объект, содержащий наши креды
print('посмотри сюда ->', conn.host, conn.login, conn.password, conn.extra) ## Тут мы вызываем методы с нашими кредамиHook – это способ подключиться к внешней системе через Connection. Любое подключение, описанное через Connection, должно выполняться через Hook. Существует множество различных хуков, например:
- Базы данных:
- PostgresHook
- MySqlHook
- SqliteHook
- OracleHook
- MsSqlHook
- API и HTTP:
- HttpHook
- Облака и хранилища:
- S3Hook
- FTPHook
Да, в целом хуков очень много. Для каждого типа подключения к сервису существует свой хук.
Все существующие хуки объединяет самый важный хук — BaseHook. Это база, на которой строятся все остальные хуки, позволяющая получить доступ к соединениям (Connections) и их параметрам. На его основе можно создавать свои кастомные хуки для любых внешних систем.
Таким образом, BaseHook — фундамент для работы с внешними источниками в AirFlow.
Принцип работы очень простой, объясню на «котиках». Самый наглядный пример — подключение к базе данных PostgreSQL.
На обычном Python мы могли бы написать код для подключения к PostgreSQL, используя строку подключения (connection string).
import psycopg2
conn_str = f'postgresql://{os.getenv("POSTGRES_USER")}:{os.getenv("POSTGRES_PASSWORD")}@postgres_source:5432/dev'
conn = psycopg2.connect(conn_str)
cursor = conn.cursor()
cursor.execute("SELECT 1;")
print(cursor.fetchone())
cursor.close()
conn.close()Если упростить, принцип таков:
Чтобы получить PostgresHook, мы используем наследование от BaseHook. BaseHook берёт по conn_id параметры подключения (Connection) из AirFlow и на их основе строится строка подключения вида:
postgresql://user:password@host:5432/dbname
Эта строка позволяет получить объект подключения (conn) для работы с базой. В наш PostgresHook можно добавить дополнительный функционал по необходимости.
Таким образом и создаются кастомные хуки.
На практике писать свои хуки приходится крайне редко, хотя сделать это достаточно просто.
Мы сознательно не использовали HttpHook на первом шаге. Наша задача — понять, как Airflow работает с Connections на базовом уровне.
Теперь, когда мы разобрались с основами, можно показать, как написать DAG с использованием HTTPHook для получения данных из API.
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.providers.http.hooks.http import HttpHook
from datetime import datetime
import requests
def extract_one_record():
hook = HttpHook(method="GET", http_conn_id="api_jsonplaceholder")
response = hook.run("/posts")
data = response.json()
first_record = data[0]
print("🔥 Первая запись из API:")
print(first_record)
with DAG(
dag_id="http_api_HttpHook",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"]
) as dag:
extract_task = PythonOperator(
task_id="extract_one_record",
python_callable=extract_one_record
)
extract_taskС точки зрения целесообразности, скрывать наш API в Connections смысла почти нет — он открытый, и любой может к нему получить доступ.
Но представь ситуацию, когда ты работаешь с закрытым API:
- нужно передавать приватный токен,
- указывать логин и пароль,
- и доступ должен быть только у тебя.
Вот тут на помощь приходят Connections: они позволяют хранить все эти секреты безопасно и использовать их в DAG’ах без хардкода.
Предлагаю рассмотреть пару часто встречаемых Connections и Hooks, чтобы раз и навсегда закрыть вопросы по их использованию.
Postgres
Было бы кощунством не рассказать о подключении к одной из самых популярных баз данных — PostgreSQL.
Для этого необходимо заполнить параметры Connection (в рамках буткемпа или общего инфрашеринга можно использовать готовые подключения)
- Conn Id: source_db
- Conn Type: Postgres
- Host: postgres
- Port: 5432
- Login: airflow
- Password: secret
- Schema: analytics. - тут указывается имя базы данных не схема данных
Для примера напишем DAG, который подключается к базе данных и выполняет команду:
SELECT True, 'БД работает';Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
def check_db_connection():
hook = PostgresHook(postgres_conn_id="source_db")
hook.run("SELECT True AS status, 'БД работает' AS message;")
with DAG(
dag_id="postgres_PostgresHook",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"]
) as dag:
extract_task = PythonOperator(
task_id="check_db_connection",
python_callable=check_db_connection
)
extract_taskЕщё одно удобство: Connections можно передавать напрямую в некоторых операторах, например:
DBTRunOperatorSQLExecuteQueryOperator
Для примера выполним тот же запрос к базе данных, используя только SQLExecuteQueryOperator.
Показать код
from airflow import DAG
from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator
from datetime import datetime
with DAG(
dag_id="check_postgres_connection",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
check_db_connection = SQLExecuteQueryOperator(
task_id="check_db_connection",
conn_id="source_db",
sql="SELECT True AS status, 'БД работает' AS message;",
show_return_value_in_logs=True
)Подводя итог данного подпункта, можно сформулировать так:
- Connection — это сохранённые параметры подключения к внешним системам.
- Hook — инструмент, который позволяет использовать эти подключения в коде AirFlow.
Проще говоря:
- Connection отвечает за «куда подключаться»,
- Hook отвечает за «что сделать с подключением».
XCom
До этого момента мы строили DAG’и, в которых задачи выполнялись независимо друг от друга. Но в реальной жизни так почти не бывает.
Обычно одна задача:
- получает данные,
- другая — обрабатывает,
- третья — использует результат.
Чтобы передавать данные между задачами, обычно используют два основных способа:
- Сохранение промежуточных результатов в хранилище, БД и т.д. (подходит, если необходимо передавать большое количество данных).
- Использование XCom (обычно применяется для передачи результирующих значений).
Давай рассмотрим простой пример — и сразу всё станет понятно:
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import random
def generate_number():
return random.randint(1, 100)
def print_number(ti):
number = ti.xcom_pull(task_ids="generate_number")
print(f"Полученное число: {number}")
with DAG(
dag_id="xcom_example_simple",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
task_generate = PythonOperator(
task_id="generate_number",
python_callable=generate_number
)
task_print = PythonOperator(
task_id="print_number",
python_callable=print_number
)
task_generate >> task_print
Как можно увидеть, пример максимально простой: функция generate_number генерирует число от 1 до 100, а функция print_number выводит это число в лог.
Что в целом происходит:
- допустим,
generate_numberвернул значение 42; - Airflow автоматически сохранил его в XCom;
print_numberдостал значение через xcom_pull.
Важно понимать: если функция имеет return <значение>, то это значение автоматически кладётся в XCom. Это можно увидеть во вкладке Admin → XCom.

В XCom можно передавать всё что угодно, например:
- строки,
- списки,
- словари,
- JSON,
- пути к файлам,
- и т.д.
Но у XCom есть одно, но очень важное ограничение — XCom НЕ предназначен для больших данных. Это связано с тем, что XCom хранится в базе Airflow, и, соответственно, большие объёмы могут её перегружать. Также важно не забывать их очищать! (DAG для очистки будет приведён в приложении в конце статьи.)
Правильный подход к использованию XCom — передавать метаданные, а не сами данные (количество строк, количество файлов, пути к файлам и т.д.).
Мы рассмотрели один из способов передачи значения в XCom с помощью return — назовём этот способ автоматическим, так как он срабатывает при завершении работы функции.
Но что делать, если нам нужно передать значение в середине функции или вообще передать несколько значений из одной функции?
На самом деле всё очень просто: это можно сделать в «ручном режиме», самостоятельно задав имя и значение.
Повторим ту же процедуру, что и в прошлом примере, только без return.
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import random
def generate_number(ti):
value_1 = random.randint(1, 100)
ti.xcom_push(key="value_1", value=value_1) ## передаем значение в переменную value_1
value_2 = random.randint(1, 100)
ti.xcom_push(key="value_2", value=value_2) ## передаем значение в переменную value_2
def print_number(ti):
number_1 = ti.xcom_pull(task_ids="generate_number", key="value_1") ## забираем значение из переменной value_1
number_2 = ti.xcom_pull(task_ids="generate_number", key="value_2") ## забираем значение из переменной value_2
print(f"Полученные числа: {number_1} и {number_2}")
with DAG(
dag_id="xcom_manual_push",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
task_generate = PythonOperator(
task_id="generate_number",
python_callable=generate_number
)
task_print = PythonOperator(
task_id="print_number",
python_callable=print_number
)
task_generate >> task_printГлавное запомнить: если в функциях мы хотим передавать или получать значения из XCom, необходимо передавать в функцию параметр объекта ti, как в примере с функциями generate_number(ti) и print_number(ti).
Для передачи и получения значений используются методы ti.xcom_push и ti.xcom_pull (push и pull ассоциируются с Git).
Важно понимать, что XCom хоть и чаще всего используется в PythonOperator, но его можно применять и в других операторах.
Например, в BashOperator всё, что выводится в stdout, перенаправляется в XCom. Также можно передать в оператор параметр do_xcom_push=True, чтобы в XCom сохранялась последняя строка, выведенная в stdout.
Если передать do_xcom_push=False, то в XCom ничего сохраняться не будет.
Рассмотрим это на примере.
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
dag_id="bash_to_bash_xcom",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
## Тут передаётся значение в XCom
generate_value_bash = BashOperator(
task_id="generate_value_bash",
bash_command='echo "42"',
do_xcom_push=True,
)
## Bash читает XCom через Jinja-шаблон
use_value_with_xcom = BashOperator(
task_id="use_value",
bash_command="""
echo "Значение из XCom: {{ ti.xcom_pull(task_ids='generate_value_bash') }}".
""", ## последняя строка stdout попадает в XCom
)
use_value_without_xcom = BashOperator(
task_id="use_value",
bash_command="""
echo "Значение из XCom: {{ ti.xcom_pull(task_ids='generate_value_bash') }}"
""",
do_xcom_push=False ## отключение записи в XCom
)
generate_value_bash >> [use_value_with_xcom, use_value_without_xcom]
Выполни данный DAG и обрати внимание, из каких тасков значения попадают в XCom, а из каких — нет.
Context и Macros
Context
На данном этапе мы уже стали достаточно уверенными пользователями Airflow.
Но сейчас мы затронем тему, которая одновременно кажется простой, но при этом играет ключевую роль в реальных задачах.
Представим ситуацию: нам нужно каждый день получать данные за вчера из внешнего API.
Самый очевидный вариант — воспользоваться библиотекой datetime.
Но что делать, если сегодня 25.01.2026, а мы обнаружили, что DAG не отработал 10.01.2026?
В таком случае нам нужно получить данные не за вчера, а за 09.01.2026 — то есть за дату, связанную с запуском DAG, а не с текущим временем.
Или другой пример.
Допустим, нам нужно записывать логи выполнения задач DAG’ов в базу данных.
Как в этом случае получить имя текущей таски, идентификатор DAG или дату запуска?
Для решения подобных задач в Airflow существуют два мощных инструмента — Context и Macros.
Context — это словарь, который Airflow передаёт в таску во время выполнения. Context содержит метаданные запуска DAG.
В нём хранится вся информация о текущем запуске, например:
- dag
- task
- ti (TaskInstance)
- ds
- execution_date
- run_id
Напишем DAG, который покажет, как обращаться к Context'у и позволит нам вывести всю информацию, хранящуюся в этой переменной.
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
from pprint import pprint
def show_context(**context):
print("ds =", context["ds"])
print("dag_id =", context["dag"].dag_id)
print("task_id =", context["task"].task_id)
print("run_id =", context["run_id"])
print("Вся информация, хранящаяся в Context:")
pprint(context)
with DAG(
dag_id="context_demo",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
task = PythonOperator(
task_id="show_context",
python_callable=show_context,
)Не пытайтесь запомнить всё это наизусть. Вам это не нужно — вы просто потратите своё время впустую. Достаточно просто посмотреть на данные.
ВАЖНО! — Airflow автоматически передаёт context, если функция принимает его. В нашем примере это выглядит так: def show_context(**context):
Macros
Macros — это шаблонные переменные Airflow, которые можно использовать в Jinja.
Например:
- {{ ds }}
- {{ ds_nodash }}
- {{ run_id }}
- {{ dag.dag_id }}
- {{ task.task_id }}По сути Macros — это то же самое, что и Context, но в формате шаблонов. Jinja-шаблон, в отличие от контекста, можно передавать в команды многих операторов, например в BashOperator.
Показать код
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
dag_id="macros_demo",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
bash_task = BashOperator(
task_id="show_macros",
bash_command="""
echo "ds = {{ ds }}"
echo "ds_nodash = {{ ds_nodash }}"
echo "dag_id = {{ dag.dag_id }}"
echo "task_id = {{ task.task_id }}"
echo "run_id = {{ run_id }}"
"""
)Повторюсь немного другими словами.
Context — это Python-уровень Airflow.
Macros — это Jinja-уровень Airflow.
Представим задачу:
Нужно сохранять файлы в каталог, зависящий от даты запуска DAG.
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from datetime import datetime
import os
def create_dir(**context):
ds = context["ds"] ## присваиваем переменной ds значение контекста `ds`
path = f"/tmp/roadmappers/data/{ds}"
os.makedirs(path, exist_ok=True) ## если каталог существует, то ошибки не будет
print(f"Создан каталог: {path}")
with DAG(
dag_id="context_macros_case_1",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
create_folder = PythonOperator(
task_id="create_folder",
python_callable=create_dir,
)
## переходим в созданный каталог и выводим полный путь, в каком каталоге находимся
show_path = BashOperator(
task_id="show_path",
bash_command='cd /tmp/roadmappers/data/{{ ds }} && pwd' ## передаем значение даты через макрос
)
create_folder >> show_pathЗапуск DAG'а с параметрами
Когда запускал DAG, можно было обратить внимание на ещё одну кнопку — Trigger DAG /w config.
Важно: если при нажатии на кнопку запуска (Trigger DAG) у тебя не появляется выбор из двух кнопок (Trigger DAG и Trigger DAG w/config), добавь в docker-compose.yaml в environment веб-сервера Airflow:
AIRFLOW__WEBSERVER__SHOW_TRIGGER_FORM_IF_NO_PARAMS: 'true'После изменения перезапусти Airflow Webserver (или подними контейнеры заново), чтобы настройка применилась.
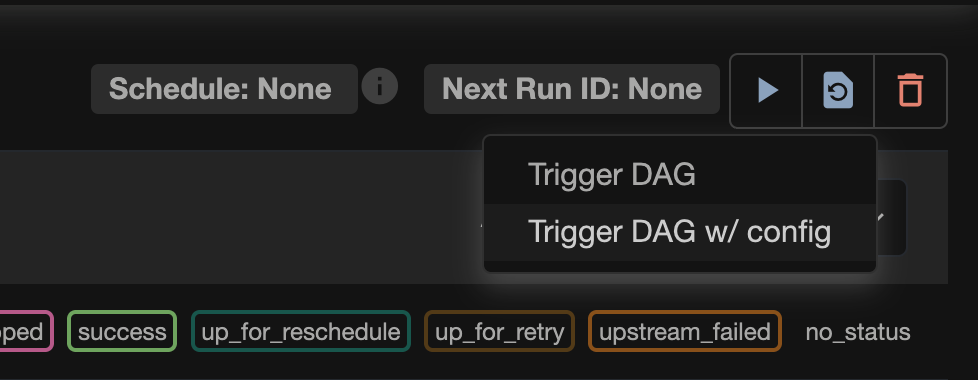
Trigger DAG /w config позволяет запускать DAG не только по расписанию, но и с параметрами. Вот примеры, когда данный функционал можно использовать:
- загрузить данные за конкретную дату
- изменить путь сохранения
- изменить chunk_size
- включить debug-режим
- обработать только одну таблицу
Предлагаю рассмотреть довольно частый бизнес-кейс: иногда нужно загрузить данные не за стандартную дату.
Возьмём предыдущий DAG и улучшим его так, чтобы можно было передать любую дату и создать каталог именно с этой датой.
Показать код
"""
Пример конфига:
```json
{
"date": "2026-01-01"
}
"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
from datetime import datetime
import os
def create_dir(**context):
conf = context["dag_run"].conf or {} ## защита для запуска без конфига
custom_date = conf.get("date", context["ds"]) ## conf.get – позволяет взять значение передаваемого параметра "date", в случае его отсутствия берется context["ds"]
path = f"/tmp/roadmappers/data/{custom_date}"
os.makedirs(path, exist_ok=True)
print(f"Создан каталог: {path}")
with DAG(
dag_id="context_macros_conf_example",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
dag.doc_md = __doc__
create_folder = PythonOperator(
task_id="create_folder",
python_callable=create_dir,
)
## для получения параметра используем Jinja { dag_run.conf.get('date', ds) }}
show_path = BashOperator(
task_id="show_path",
bash_command="""
echo "Дата запуска: {{ ds }}"
cd /tmp/roadmappers/data/{{ dag_run.conf.get('date', ds) }} && pwd
"""
)
create_folder >> show_pathДля передачи необходимо вставить параметры в JSON-формате (описанные в комментарии к DAG) в соответствующую ячейку.
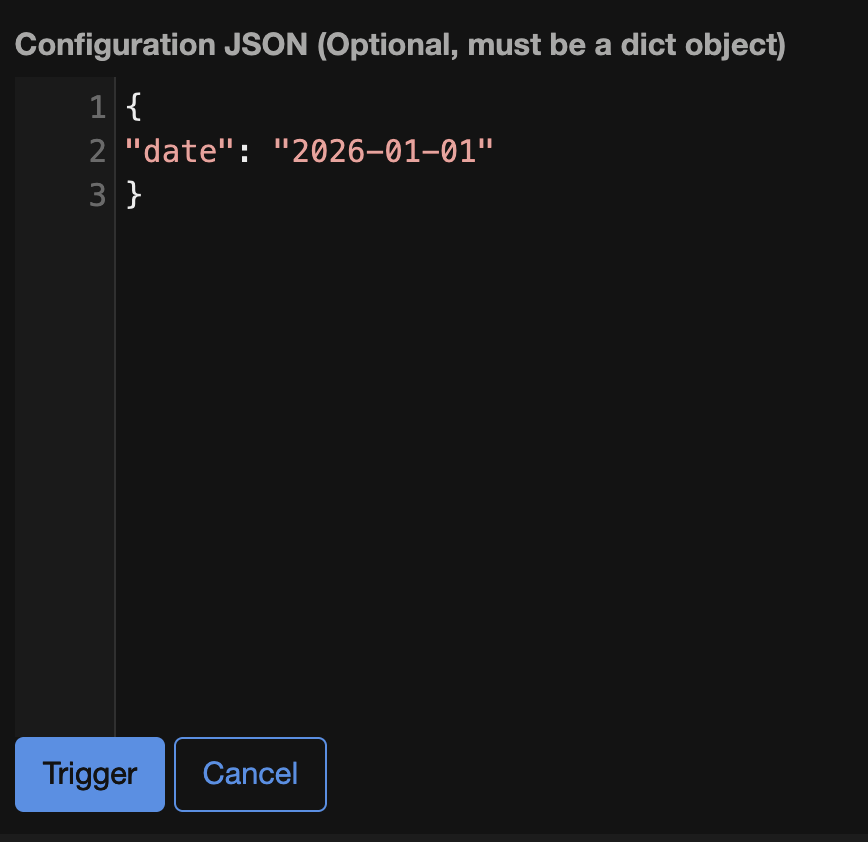
И запускаем DAG – кнопка Trigger
Посмотрим на результаты BashOperator'а при запуске без параметра и с параметром.
Без параметра
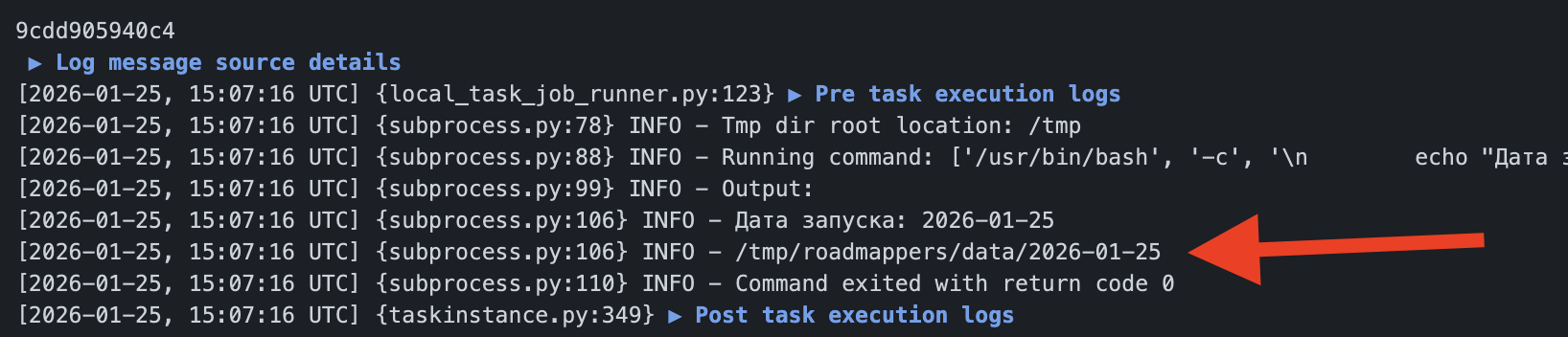
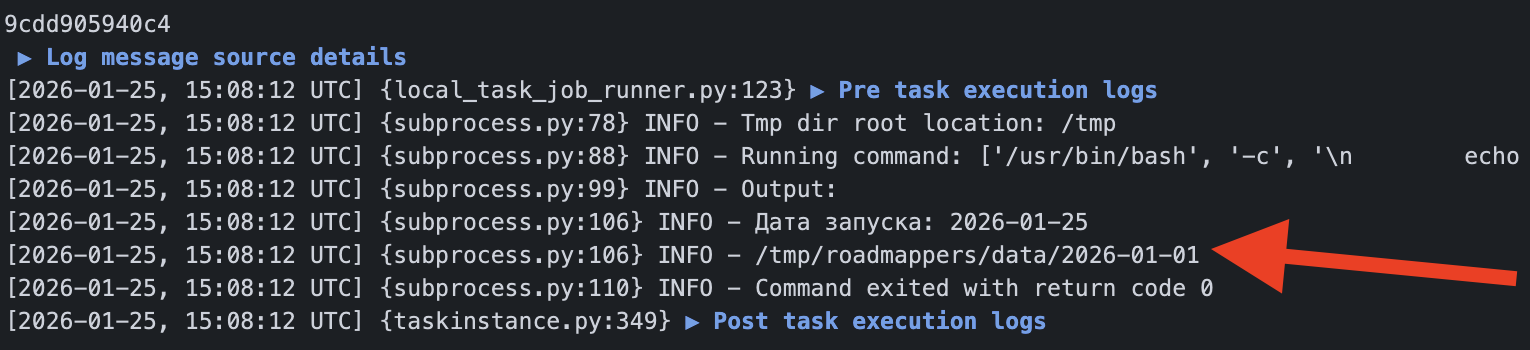
С параметром
Теперь мы понимаем, что DAG — это не просто набор тасок, а процесс, который всегда выполняется в определённом контексте: с датой запуска, параметрами, метаданными и состоянием.
Теперь плавно переходим к следующей теме задавая себе вопросы:
- А что делать, если часть тасок упала?
- Должны ли запускаться следующие?
Trigger Rules
Посмотри на DAG
Что будет, если:
- Task_1 – выполнится успешно
- Task_2 - упадёт с ошибкой
Запустится ли Task_3?
Нет, потому что по умолчанию параметр trigger_rule = all_success, а это значит, что запуск следующей таски произойдёт тогда, когда выполнятся все предыдущие. Это самый часто встречаемый сценарий, поэтому он и используется по умолчанию
Основные Trigger Rules
| Trigger Rule | Когда запускается |
|---|---|
| all_success (по умолчанию) | все upstream success |
| all_failed | все upstream failed |
| one_success | хотя бы один success |
| one_failed | хотя бы один failed |
| none_failed | нет failed |
| none_failed_min_one_success | нет failed и хотя бы один success |
| all_done | все завершились (success/failed/skipped) |
Переходим сразу к практике
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
from datetime import datetime
def ok_task():
print("OK task success")
def fail_task():
raise Exception("Task failed")
def final_task():
print("Final task executed")
with DAG(
dag_id="trigger_rules_demo",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
) as dag:
## таска без ошибок
task_ok = PythonOperator(
task_id="task_ok",
python_callable=ok_task,
)
## таска с ошибками
task_fail = PythonOperator(
task_id="task_fail",
python_callable=fail_task,
)
## таска с настроенным trigger_rule
task_final = PythonOperator(
task_id="task_final",
python_callable=final_task,
trigger_rule=TriggerRule.ALL_DONE, ## ключевая строка, отвечающая за правило триггера таски
)
[task_ok, task_fail] >> task_final
Посмотрим на результат:
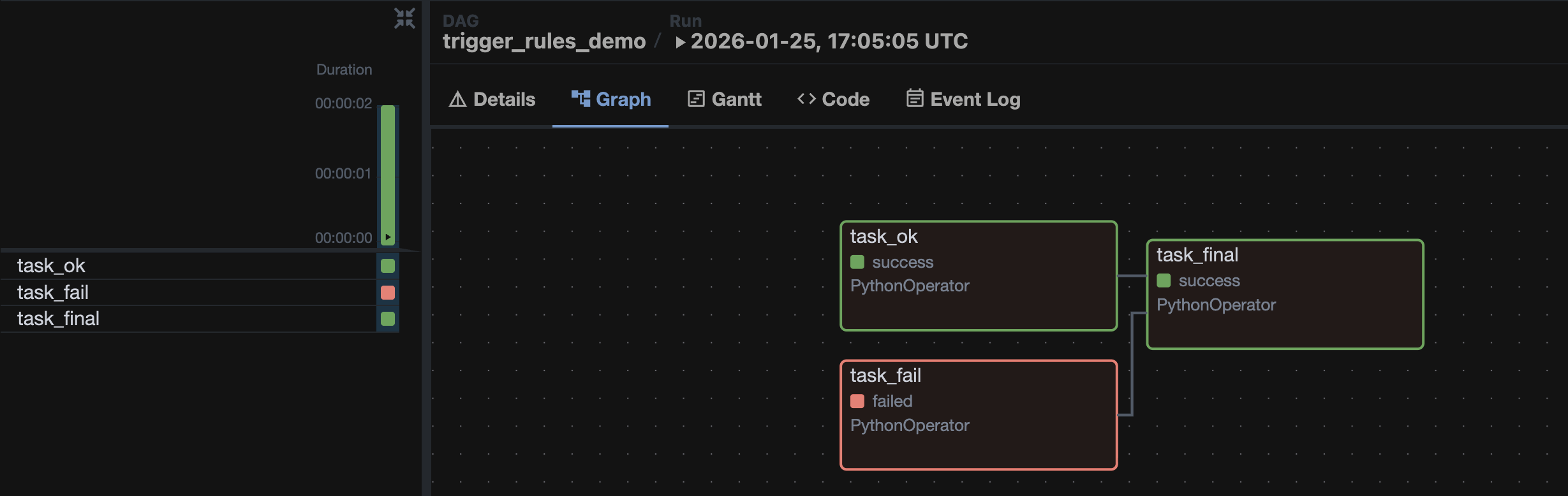
Здесь мы видим, что таска task_final выполнилась, даже несмотря на то, что task_fail упала с ошибкой.
Это связано с настройкой trigger_rule=TriggerRule.ALL_DONE, так как ALL_DONE разрешает выполнение таски, если предыдущие таски завершились со статусами success, failed или skipped.
Чтобы менять правила, не забудьте выполнить импорт: from airflow.utils.trigger_rule import TriggerRule.
Такую практику можно применять в кейсах с логированием, когда независимо от исхода выполнения DAG необходимо записать лог.
Ещё один кейс:
Когда мы получаем данные из нескольких разных источников, но нет гарантии, что они содержат необходимые нам данные.
Самостоятельно попробуй поработать с другими правилами и подумай, в каких задачах можно было бы использовать выбранное правило.
Retries / SLA / Callbacks
Retries / SLA / Callbacks — обычные параметры, передаваемые в операторах. Их достаточно часто используют в реальных пайплайнах, в случаях:
- API может временно не отвечать,
- база может быть недоступна,
- таска может упасть из-за сети,
- бизнес требует SLA: «данные должны быть готовы до 09:00»,
- нужно уведомлять о сбоях.
Retries
Идея передачи параметра retries в том, что если задача упала, Airflow попробует выполнить её ещё раз.
Примеры бизнес-кейсов:
- Мы обращаемся к API, которое иногда падает.
- Теряется соединение с базой данных.
Чаще к retries добавляют параметр retry_delay — время ожидания перед повторным запуском. retries принимает целое число, retry_delay — тип timedelta (не забудьте его импортировать).
Пример DAG:
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import random
def unstable_task():
if random.random() < 0.7:
raise Exception("API временно недоступно")
print("Успешный запрос 🎉")
default_args = {
"retries": 3, ## 3 попытки перезапустить DAG
"retry_delay": timedelta(seconds=10), ## между попытками ждем 10 секунд
}
with DAG(
dag_id="retries_example",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
default_args=default_args,
tags=["roadmappers"],
) as dag:
task = PythonOperator(
task_id="unstable_task",
python_callable=unstable_task,
)
В случае, если random.random() < 0.7, таска получает статус up_for_retry.
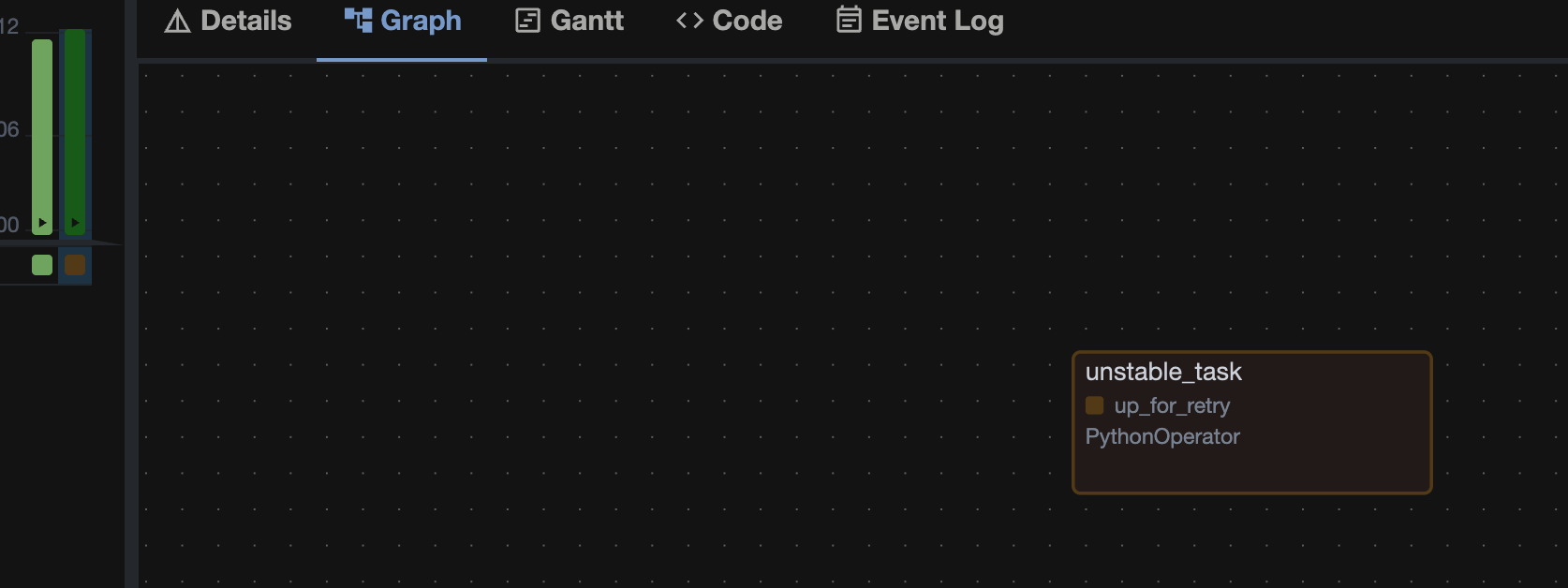
SLA
SLA — это «дедлайн» задачи. Если таска не завершилась вовремя, Airflow отправляет сигнал.
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import time
def slow_task():
time.sleep(60)
print("Задача выполнена")
with DAG(
dag_id="sla_example",
start_date=datetime(2026, 1, 24),
schedule_interval="@daily",
catchup=True,
tags=["roadmappers"],
) as dag:
task = PythonOperator(
task_id="slow_task",
python_callable=slow_task,
sla=timedelta(seconds=7), ## Задаем SLA
)Увидеть нарушение SLA можно в Browse → SLA Misses
Callbacks
Callbacks — это функции, которые вызываются:
- при успехе
- при ошибке
- при ретрае
- при SLA нарушении
| Callback(параметр) | Когда вызывается |
|---|---|
| on_success_callback | успех |
| on_failure_callback | ошибка |
| on_retry_callback | повтор |
| sla_miss_callback | нарушение SLA |
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def task_func():
raise Exception("Ошибка 😈")
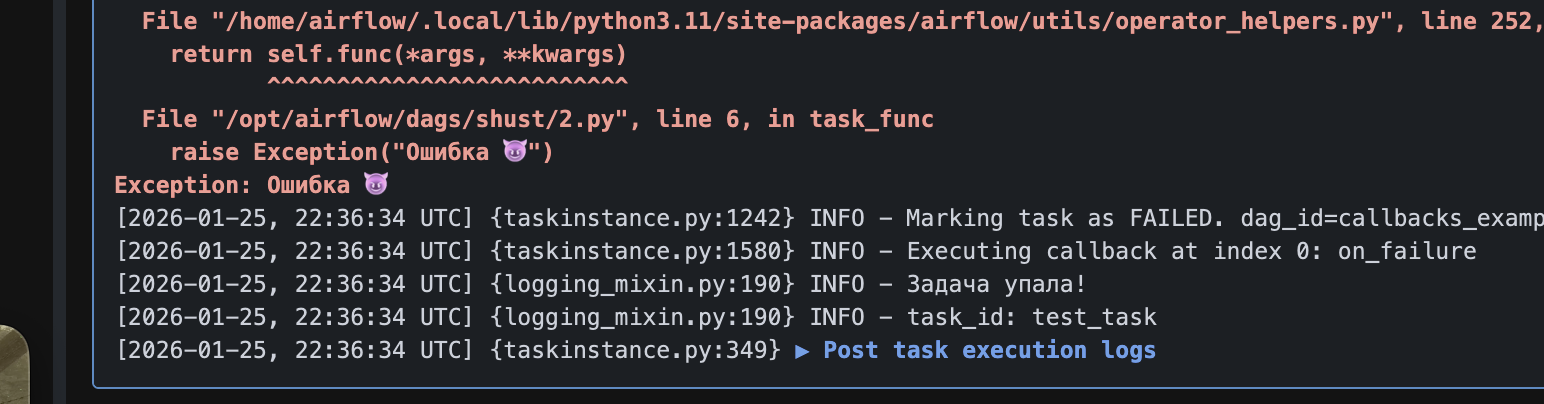
def on_failure(context):
print("Задача упала!")
print("task_id:", context["task_instance"].task_id)
def on_success(context):
print("Задача успешна!")
with DAG(
dag_id="callbacks_example",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
task = PythonOperator(
task_id="test_task",
python_callable=task_func,
on_failure_callback=on_failure,
on_success_callback=on_success,
)Вот что мы увидем в логах.
А теперь объединим все параметры в одной таске. Результат изучи самостоятельно!
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import random
import time
def api_task():
time.sleep(3)
if random.random() < 0.5:
raise Exception("API error")
print("Данные получены")
def failure_callback(context):
print("Ошибка в таске:", context["task_instance"].task_id)
default_args = {
"retries": 2,
"retry_delay": timedelta(seconds=3),
}
with DAG(
dag_id="retries_sla_callbacks_real_case",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
default_args=default_args,
tags=["roadmappers"],
) as dag:
api_task_operator = PythonOperator(
task_id="api_task",
python_callable=api_task,
sla=timedelta(seconds=2),
on_failure_callback=failure_callback,
)По итогам пункта:
Retries — делают пайплайн устойчивым к временным сбоям
SLA — контролирует время выполнения задач
Callbacks — позволяют реагировать на ошибки и успехи
Вместе они превращают DAG из «скрипта» в промышленный пайплайн.
Branching
До этого мы рассматривали прямолинейные DAG’и: есть таска А, затем В и С, и все они выполняются друг за другом или параллельно. Вот так:
- последовательно

- параллельно
В любом случае все таски выполнялись друг за другом. А что если необходимо ввести какую-нибудь логику: например, при одних условиях выполняются одни таски, при других — другие.
Приведём простой пример из жизни:
Наша задача — выйти на прогулку.
/-> берём зонт -> выходим -> открываем зонт -> гуляем
(если дождь)/
Одеваемся -> Обуваемся -> Задаемся вопросом какая погода на улице?
(если солнце)\
\-> выходим -> гуляем Как видно из примера, в зависимости от погоды, наши действия будут меняться
Тоже самое можно сделать и в AirFlow с помощью – Branching
Branching — это возможность DAG’а выбирать путь выполнения.
Кейсы где это применяемо:
- Проверка наличия данных
- если данных нет -> пропускаем обработку
- если есть -> запускаем пайплайн
- Разная логика обработки
- если размер файла > 1GB -> Spark
- если < 1GB -> Pandas
- Поведение по дате
- если сегодня понедельник -> полный расчёт
- иначе -> инкрементальный
Рассмотри пример кейса 2(абстрактно)
Мы загружаем данные из API
- если строк больше 50 -> выводим
heavy processing - если меньше -> выводим
light processing
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator, BranchPythonOperator
from airflow.operators.empty import EmptyOperator
from datetime import datetime
import random
def choose_branch():
value = random.randint(1, 100)
print(f"Количество строк: {value}")
if value > 50:
return "heavy_task"
else:
return "light_task"
def heavy():
print("Heavy processing")
def light():
print("Light processing")
with DAG(
dag_id="branching_example",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
tags=["roadmappers"],
) as dag:
start = EmptyOperator(task_id="start")
branch = BranchPythonOperator(
task_id="branch_task",
python_callable=choose_branch,
)
heavy_task = PythonOperator(
task_id="heavy_task",
python_callable=heavy,
)
light_task = PythonOperator(
task_id="light_task",
python_callable=light,
)
end = EmptyOperator(task_id="end", trigger_rule="none_failed_min_one_success")
start >> branch >> [heavy_task, light_task] >> end
Получаем следующий DAG:
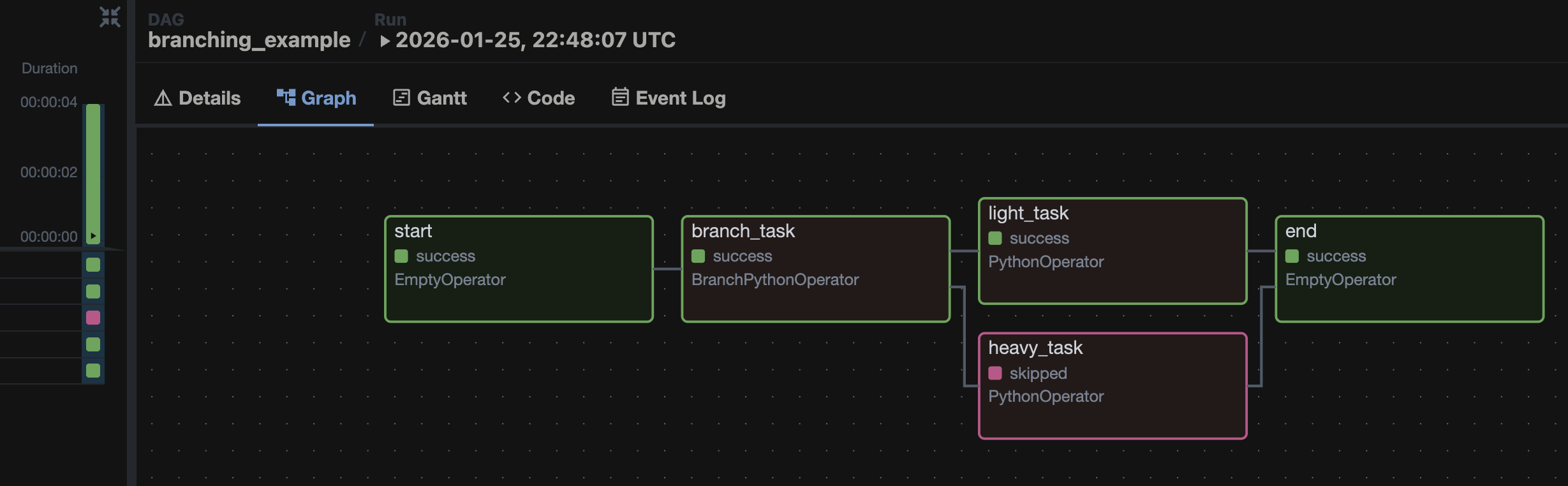
Важные моменты Branching:
- Для ветвления используется
BranchPythonOperator, который возвращает имя таски, которую необходимо запустить (определяет, по какой ветке идти). - Выполняется только один путь, остальные таски помечаются как
SKIPPED, поэтому таска после выхода из ветвления должна иметь правилоtrigger_rule="none_failed_min_one_success". - Нельзя использовать одни и те же таски в двух ветках. Если нужен такой функционал, создаём ещё один
BranchPythonOperatorи не забываем в конце добавить ветвление.
Branching нужен, чтобы DAG был не скриптом, а логикой.
Sensor
Sensor — это задача, которая ждёт, пока выполнится условие.
Кейс для применения:
У компании есть 5 филиалов в разных часовых поясах. Каждый филиал ежедневно выгружает отчёт на свой FTP-сервер. Время выгрузки нефиксированное и может отличаться. Наша задача — автоматически обнаружить появление файлов, загрузить их в хранилище и обработать.
Существует большое количество различных сенсоров. Вот примеры по типам:
| Тип | Sensor | Что ждёт |
|---|---|---|
| Время | TimeSensor | конкретное время |
| Файл | FileSensor | файл |
| БД | SqlSensor | результат запроса |
| API | HttpSensor | ответ API |
| DAG | ExternalTaskSensor | другую задачу |
| Cloud | S3/GCS Sensors | объект в облаке |
| Airflow | DatasetSensor | обновление dataset |
Предлагаю перейти к самому сложному примеру из всех, которые ты видел здесь.
Смысл очень простой: моделируем кейс, описанный выше.
Два сенсора отслеживают два каталога (после запуска отслеживание происходит в течение 60 секунд, проверка сенсором каталога каждые 10 секунд).
Параллельно в один из каталогов попадает сгенерированный другой таской файл (как будто кто-то положил его туда через 20 секунд после старта всего DAG).
Дальше происходит ветвление: если в каталоге есть файл — запускается задача его обработки (абстрактно), если файла нет — просто записывается лог об отсутствии файла (абстрактно).
Приступим:
Показать код
from airflow import DAG
from airflow.operators.python import PythonOperator, BranchPythonOperator
from airflow.operators.empty import EmptyOperator
from airflow.sensors.filesystem import FileSensor
from airflow.utils.task_group import TaskGroup
from airflow.utils.trigger_rule import TriggerRule
from datetime import datetime
import time
import os
BRANCHES = ["branch_1", "branch_2"]
## ветвление
def decide_branch(branch):
path = f"/tmp/branches/{branch}/report.csv"
if os.path.exists(path):
return f"check_files.process_{branch}"
return f"check_files.skip_{branch}"
## имитация обработки
def process_file(branch):
print(f"Обработка файла из {branch}")
## генерация файла (имитация загрузки файла в каталог с ожиданием в 20 секунд после старта)
def generate_file():
## имитация ожидания
time.sleep(20)
path = "/tmp/branches/branch_1"
os.makedirs(path, exist_ok=True)
file_path = os.path.join(path, "report.csv")
with open(file_path, "w", encoding="utf-8") as f:
f.write("date,value\n2026-01-26,42\n")
print(f"Файл создан: {file_path}")
with DAG(
dag_id="sensors_branches_advanced_fixed",
start_date=datetime(2026, 1, 1),
schedule_interval=None,
catchup=False,
) as dag:
generate_file_task = PythonOperator(
task_id=f"generate_file",
python_callable=generate_file,
)
start = EmptyOperator(task_id="start")
with TaskGroup("check_files") as check_files:
for branch in BRANCHES:
## создаём все задачи заранее циклом
wait_file = FileSensor(
task_id=f"wait_file_{branch}",
filepath=f"/tmp/branches/{branch}/report.csv",
poke_interval=10, ## интервалы между проверками сенсора
timeout=60, ## время работы сенсора до того, как он упадёт с ошибкой
mode="reschedule", ## определяет как именно сенсор будет “ждать”
)
branch_task = BranchPythonOperator(
task_id=f"branch_{branch}",
python_callable=decide_branch,
op_args=[branch],
trigger_rule=TriggerRule.ALL_DONE,
)
process = PythonOperator(
task_id=f"process_{branch}",
python_callable=process_file,
op_args=[branch],
)
## имитация логирвоания
skip = EmptyOperator(task_id=f"skip_{branch}")
## порядок соединения внутги группы
wait_file >> branch_task
branch_task >> process
branch_task >> skip
end = EmptyOperator(task_id="end", trigger_rule=TriggerRule.NONE_FAILED_MIN_ONE_SUCCESS)
## общий порядок DAG'а
start >> check_files >> end
start >> generate_file_taskПолучается DAG следующего вида:
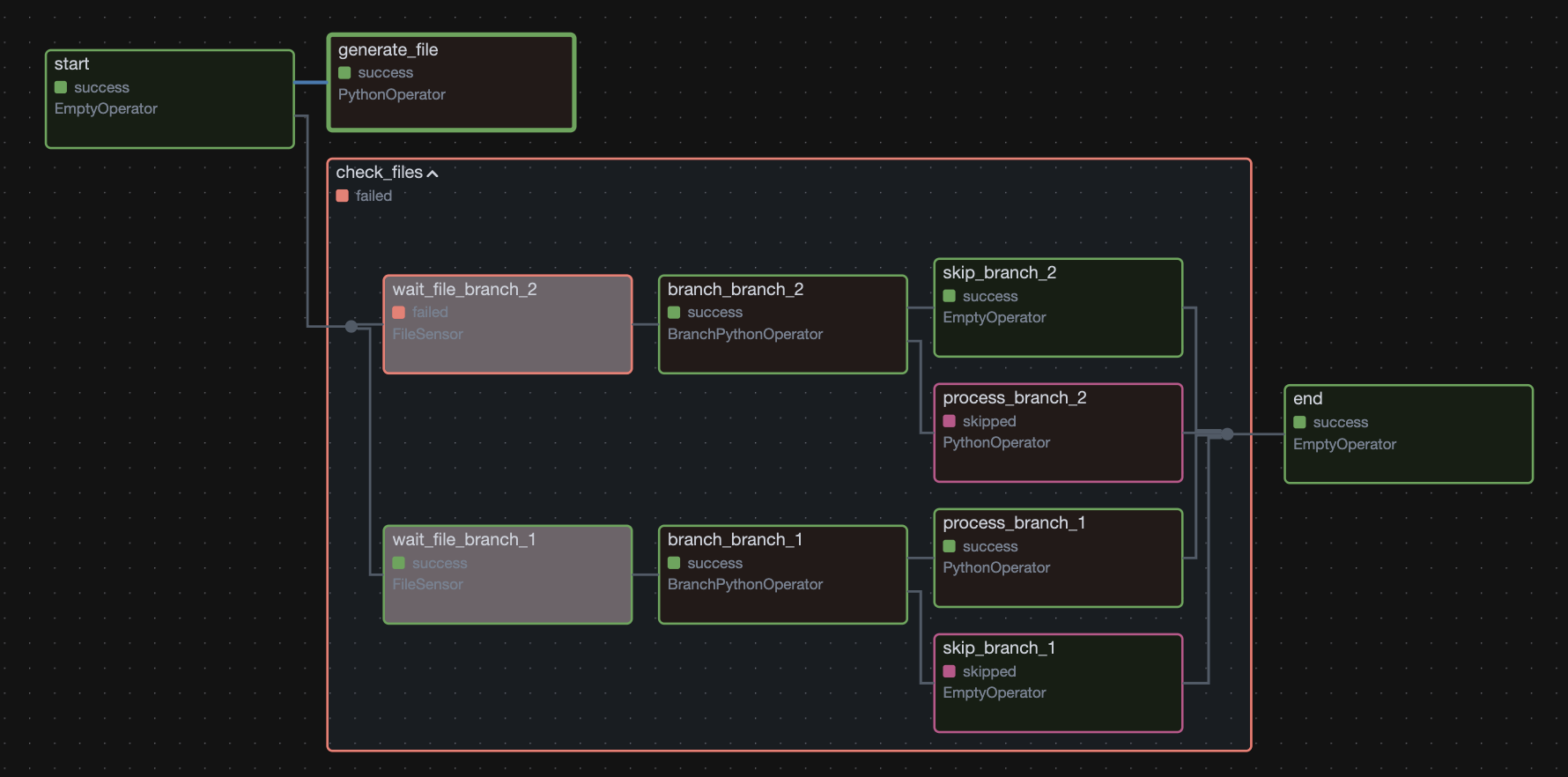
В результате выполнения мы видим, что по ветке 1 файл найден (что логично — он туда генерируется), а на 2-й ветке файла нет.
Как ты можешь заметить, в этом примере собраны многие темы, которые мы уже прошли. Есть и ветвление, и группировка тасок, и настройка триггеров, и даже передача параметров в функции через параметры оператора. Но есть и то, чего мы ещё не видели — начнём, конечно, с сенсора.
У сенсора есть три важных параметра:
poke_interval— через какие промежутки времени сенсор будет проверять условия,timeout— общее время работы сенсора,mode— как будет проходить ожидание сенсора. Есть два типа:poke— процесс задачи блокируется, тем самым блокируя воркер,reschedule— воркер не простаивает, можно обслуживать больше задач, но нагружает планировщик. В продовых задачах используется чаще всего.
Также обращаю внимание на цикл for branch in BRANCHES: — он позволяет генерировать таски, если их логика одинаковая.
Пример из практики: когда необходимо обновлять две абсолютно одинаковые базы данных (одна продовая, другая — её реплика), в цикле передавая креды.
Сенсоры позволяют DAG’ам «подстраиваться» под внешние события, а правильный режим работы и таймаут делают их эффективными без блокировки воркеров.
Итог
Airflow — это не просто планировщик задач, а язык описания бизнес-процессов обработки данных.
Теперь ты умеешь:
- строить сложные DAG’и,
- управлять конфигурацией,
- передавать данные между задачами,
- писать условную логику,
- работать с внешними системами,
- проектировать устойчивые пайплайны.
Приложение
DAG для отчиски XCom
Показать код
"""
Ежедневное удаление данных из XCom, которые хранятся больше суток, со всех ДАГов
"""
from airflow.models import DAG
from airflow.utils.db import provide_session
from airflow.models import XCom
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from datetime import timedelta
from datetime import datetime
import logging
logger = logging.getLogger("airflow.task")
DEFAULT_ARGS = {
"owner": "roadmappers",
"retries": 2,
"retry_delay": 600,
"start_date": datetime(2025, 7, 20),
}
with DAG(
dag_id="TECH_Clean_Xcom",
default_args=DEFAULT_ARGS,
schedule_interval="@daily", ## каждый день
description="Очистка XCom каждый день",
tags=["clean_xcom", "roadmappers"],
) as dag:
@provide_session
def cleanup_xcom(session=None, **context):
## удаляем данные, которые хранятся более суток
num_rows_deleted = 0
date_limit = context["logical_date"]
logger.info(f"Удаляем данные вплоть до {date_limit}")
try:
num_rows_deleted = (
session.query(XCom).filter(XCom.timestamp <= date_limit).delete()
)
session.commit()
except:
session.rollback()
if num_rows_deleted == 0:
logger.info(f"Нет записей для удаления")
else:
logger.info(f"Удалено {num_rows_deleted} строк из XCom")
clean_xcom = PythonOperator(
task_id="cleanup_xcom",
python_callable=cleanup_xcom,
provide_context=True,
dag=dag,
)
dag_start = EmptyOperator(task_id="start")
dag_end = EmptyOperator(task_id="end", trigger_rule="none_failed")
dag.doc_md = __doc__
dag_start >> clean_xcom >> dag_end