Apache Iceberg
Что это такое
Apache Iceberg — это открытый табличный формат для озёр данных. Он даёт Data Lake свойства полноценного хранилища:
- транзакции (ACID),
- историю изменений (snapshots / time travel),
- эволюцию схемы без переливки данных,
- быстрый SQL-доступ.
Зачем он нужен
DWH хорошо работают со структурированными данными, но дорогие и жёсткие. Data Lake дешёвые и гибкие, но без транзакций и контроля качества.
Iceberg — это компромисс:
- хранение в озере,
- работа как с таблицами в DWH.
Ключевые преимущества
- ACID-транзакции без централизованной БД
- Time Travel — чтение таблицы в прошлом
- Эволюция схемы и партиций без перезагрузки данных
- Совместимость со Spark, Flink, Trino, Dremio и др.
- Масштабируемость до петабайтных объёмов
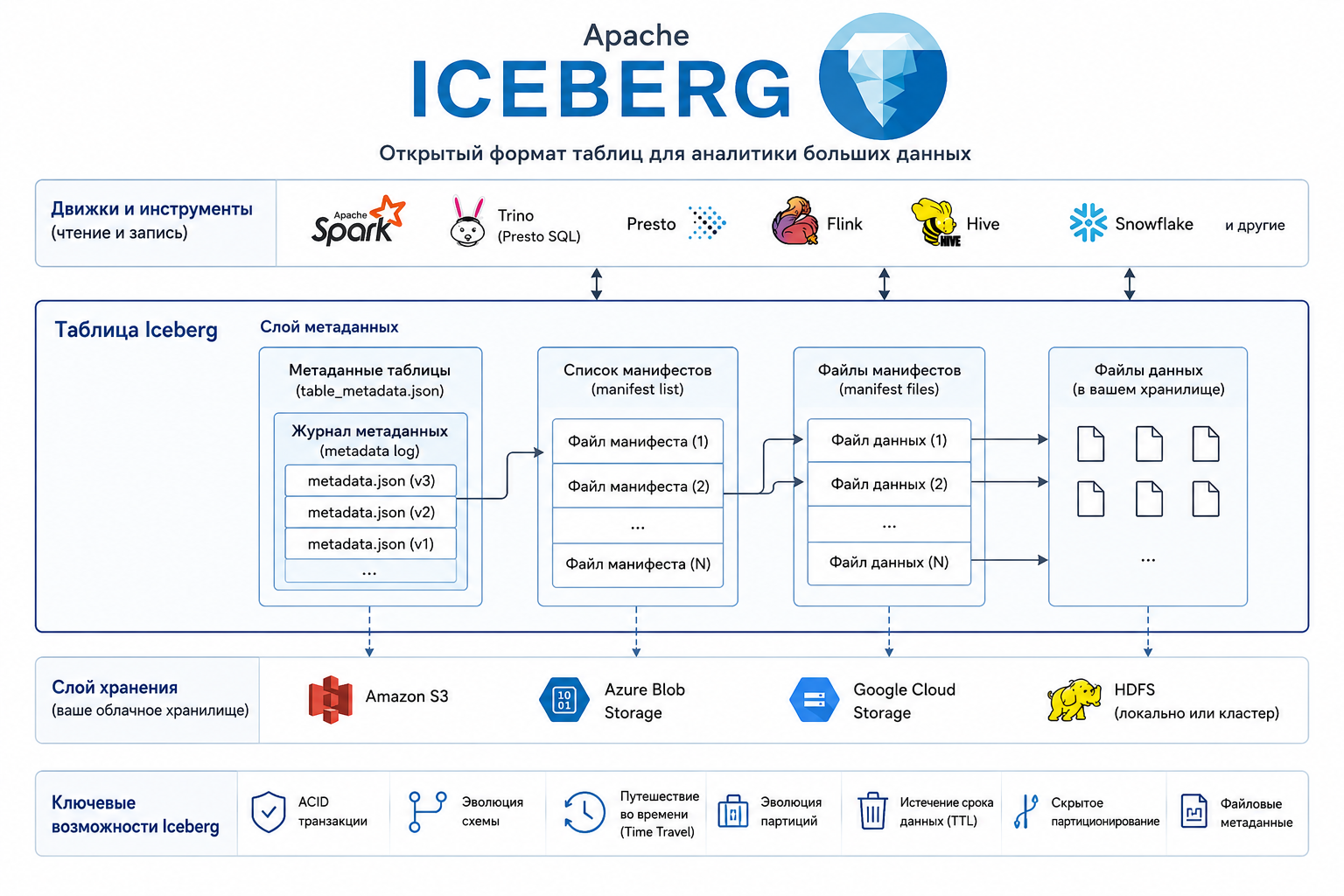
Архитектура Iceberg (очень кратко)
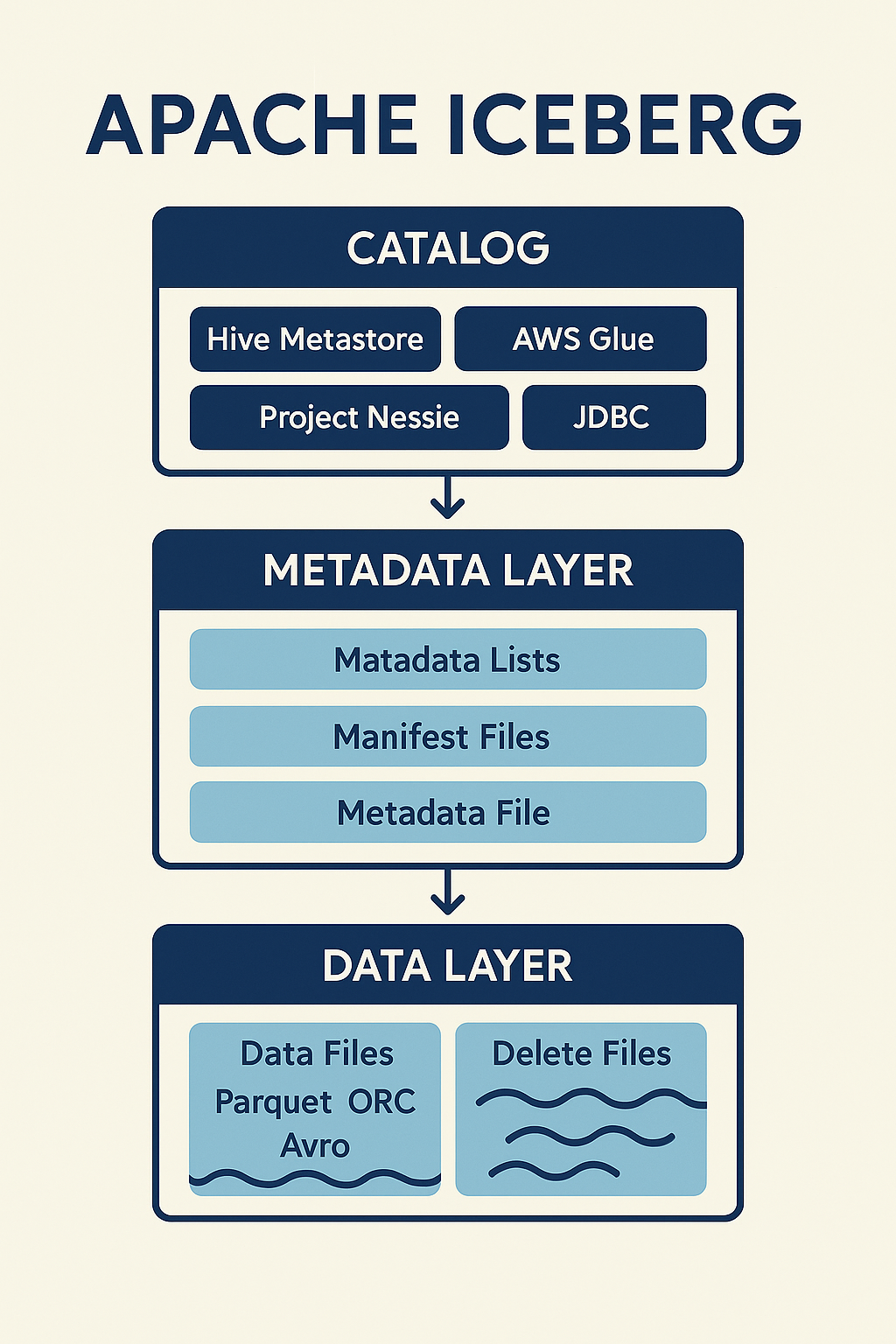
1) Data Layer
Файлы данных (Parquet/ORC/Avro) + delete files.
2) Metadata Layer
Манифесты, снапшоты, схема, партиции, статистика.
3) Catalog Layer
Точка входа для движков (Hive Metastore, Glue, Nessie, JDBC/REST).
Файлы удаления и стратегии записи
Iceberg поддерживает два подхода:
Copy-on-Write (COW)
- переписывает файлы при изменении;
- проще читать, дороже писать.
Merge-on-Read (MOR)
- фиксирует изменения в delete files;
- быстро пишет, чуть тяжелее читать.
Примеры работы с Iceberg
Ниже примеры разбиты по отдельным операциям.
1) Запуск Spark-сессии с Iceberg
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("IcebergExample")
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.my_catalog.type", "hive")
.config("spark.sql.catalog.my_catalog.uri", "thrift://localhost:9083")
.getOrCreate()
)2) Создание таблицы
CREATE TABLE my_catalog.db.orders (
order_id BIGINT,
customer_id BIGINT,
amount DECIMAL(10,2),
created_at TIMESTAMP
)
USING iceberg
PARTITIONED BY (days(created_at))3) Time Travel по snapshot-id
SELECT * FROM my_catalog.db.orders VERSION AS OF 9182736454) Time Travel по времени
SELECT * FROM my_catalog.db.orders TIMESTAMP AS OF '2025-09-28 14:00:00'5) Компактизация файлов
CALL my_catalog.system.rewrite_data_files('db.orders')6) Очистка старых снапшотов
CALL my_catalog.system.expire_snapshots('db.orders')
WHERE committed_at < TIMESTAMP '2025-09-01 00:00:00'7) Удаление orphan-файлов
CALL my_catalog.system.remove_orphan_files('db.orders')Пример MERGE и DELETE
MERGE (обновление и вставка)
MERGE INTO my_catalog.db.orders t
USING my_catalog.db.orders_updates s
ON t.order_id = s.order_id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *DELETE (удаление по условию)
DELETE FROM my_catalog.db.orders
WHERE amount = 0Iceberg vs Delta vs Hudi (в двух словах)
Все три — open table formats для Lakehouse. Отличия чаще всего в экосистеме и деталях.
| Формат | Сильная сторона | Где часто используют |
|---|---|---|
| Iceberg | Портируемость, нейтральность к движкам | Spark, Trino, Flink |
| Delta | Глубокая интеграция с Databricks | Databricks, Spark |
| Hudi | Хорош в стриминге и CDC-сценариях | Spark, Flink |
На практике выбор часто зависит от стека и команды, а не только от формата.