Индексы
Объяснение на пальцах
1) Таблица без индексов и партиций (просто мешок)

Есть один большой мешок, куда всё ссыпают как попало.
CREATE TABLE bags (
number_cube INT
);Как работает:
- чтобы найти
number_cube=5, СУБД просматривает весь мешок (full scan); - запись быстрая, поиск медленный.
2) Таблица с партициями (несколько мешков)
Мы делим данные по правилу, например по цвету или диапазону.

CREATE TABLE partitioned_bags (
number_cube INT,
color VARCHAR(20)
)
PARTITION BY LIST (color);
CREATE TABLE bags_red PARTITION OF partitioned_bags FOR VALUES IN ('red');
CREATE TABLE bags_blue PARTITION OF partitioned_bags FOR VALUES IN ('blue');Как работает:
- если ищем
color='red', СУБД лезет только в нужную партицию; - если фильтр по партиции не задан, проверяем все мешки.
Плюс: быстрый поиск по ключу партиции.
Минус: чуть сложнее сопровождение.
Если данных мало (условно меньше 1 млн строк), партиции часто не дают выигрыша.
3) Таблица с индексом (мешок + каталог)
Индекс — это отдельный «каталог», где хранится отсортированный список ключей и ссылка на строку в таблице.
CREATE TABLE indexed_bags (
number_cube INT
);
CREATE INDEX idx_number ON indexed_bags (number_cube);Как работает:
- СУБД находит ключ в индексе
- получает адрес строки
- читает только нужные строки, а не весь мешок
Плюс: быстрый поиск.
Минус: запись медленнее и индекс занимает место на диске.
Когда что использовать
- Просто таблица без индексов — если запись очень частая, а чтение редкое (логи).
- Партиции — когда данные логично делятся по ключу (дата, регион, сегмент).
- Индексы — когда часто фильтруем, соединяем или сортируем по столбцу.
Индексы: кратко и по делу
Индекс — это структура, которая ускоряет поиск и сортировку. Если индекс поставлен не туда, он может даже замедлить систему.
Когда индексы полезны
- первичные и внешние ключи
- столбцы в
WHERE - столбцы в
JOIN - столбцы в
ORDER BY - столбцы в
GROUP BY - высокоселективные поля (много уникальных значений)
Когда индексы могут быть вредны
- таблица часто обновляется
- низкая кардинальность (мало уникальных значений)
- выборка очень большого процента строк (условно больше 5%)
Основные виды индексов
Кластеризованный и некластеризованный
- Кластеризованный сортирует физический порядок строк в таблице.
- Некластеризованный — отдельная структура, которая хранит ссылки на строки.

| Тип | Что делает | Особенность |
|---|---|---|
| Кластеризованный | хранит строки в порядке ключа | может быть только один |
| Некластеризованный | хранит ссылки на строки | может быть много |
Уникальный и неуникальный
- Уникальный — значения не повторяются.
- Неуникальный — значения могут повторяться.
Простой и составной
- Простой — по одному столбцу.
- Составной — по нескольким столбцам, порядок важен.
Индексы по структуре
1) B-Tree (самый популярный)
Используется в 90% случаев. Данные отсортированы, поиск за O(log n).
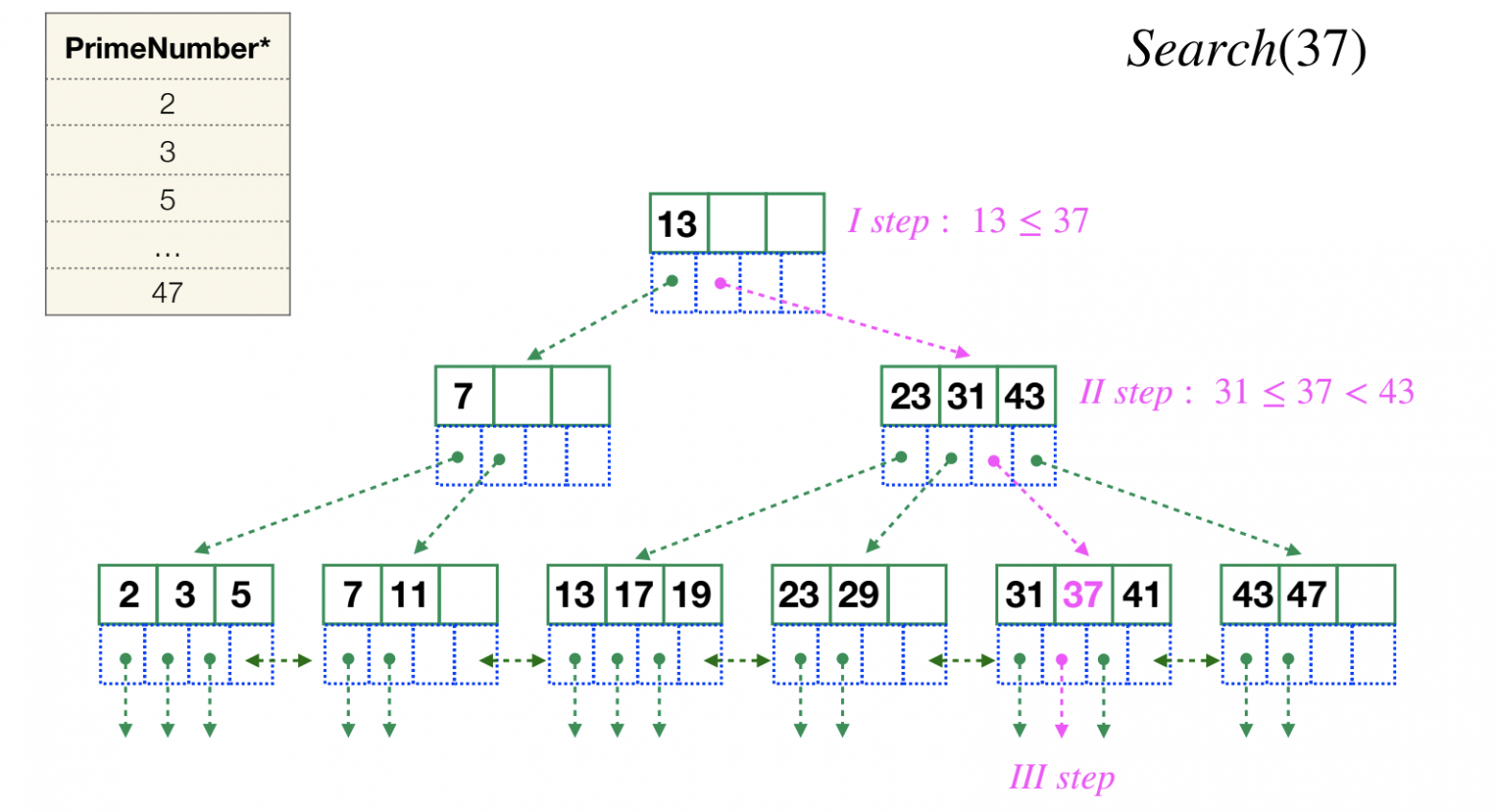
CREATE INDEX idx_user ON test.user (id);B+Tree — улучшенная версия, где данные в листьях. Отлично подходит для диапазонов.
2) Реверсивный индекс
Ключ хранится в обратном порядке, чтобы равномерно распределять вставки. Полезно для последовательных ID, чтобы не было «горячей точки».
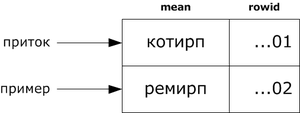
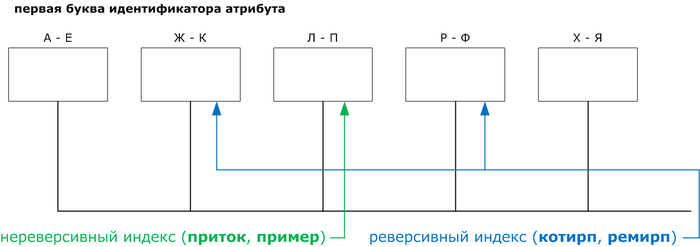
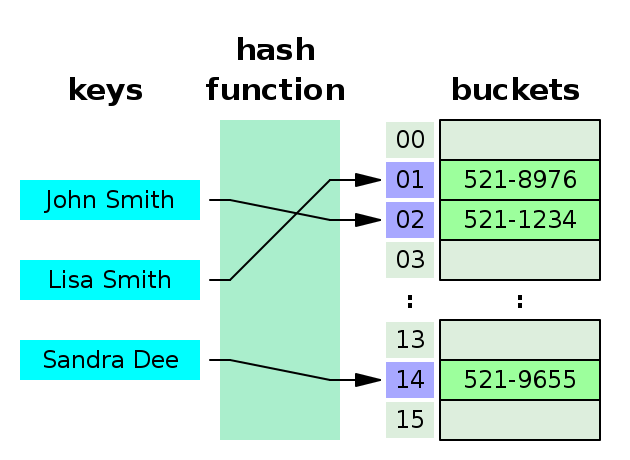
3) Hash-индекс
Быстрый доступ по точному совпадению. Не подходит для диапазонных запросов.
Если хочется отдельно разобраться, что такое хеш, чем он отличается от шифрования,
почему хеш-таблицы дают средний поиск O(1) и как это связано с Hash Join,
смотри страницу Хеш и хеш-таблицы.
4) Bitmap-индекс
Хорош для низкой кардинальности и логических операций. Чаще используется в аналитике.

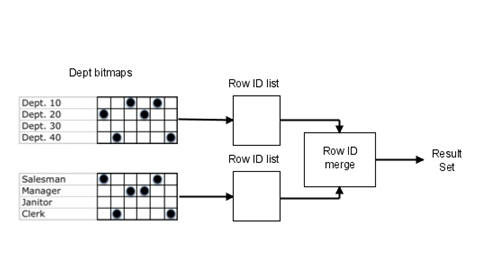
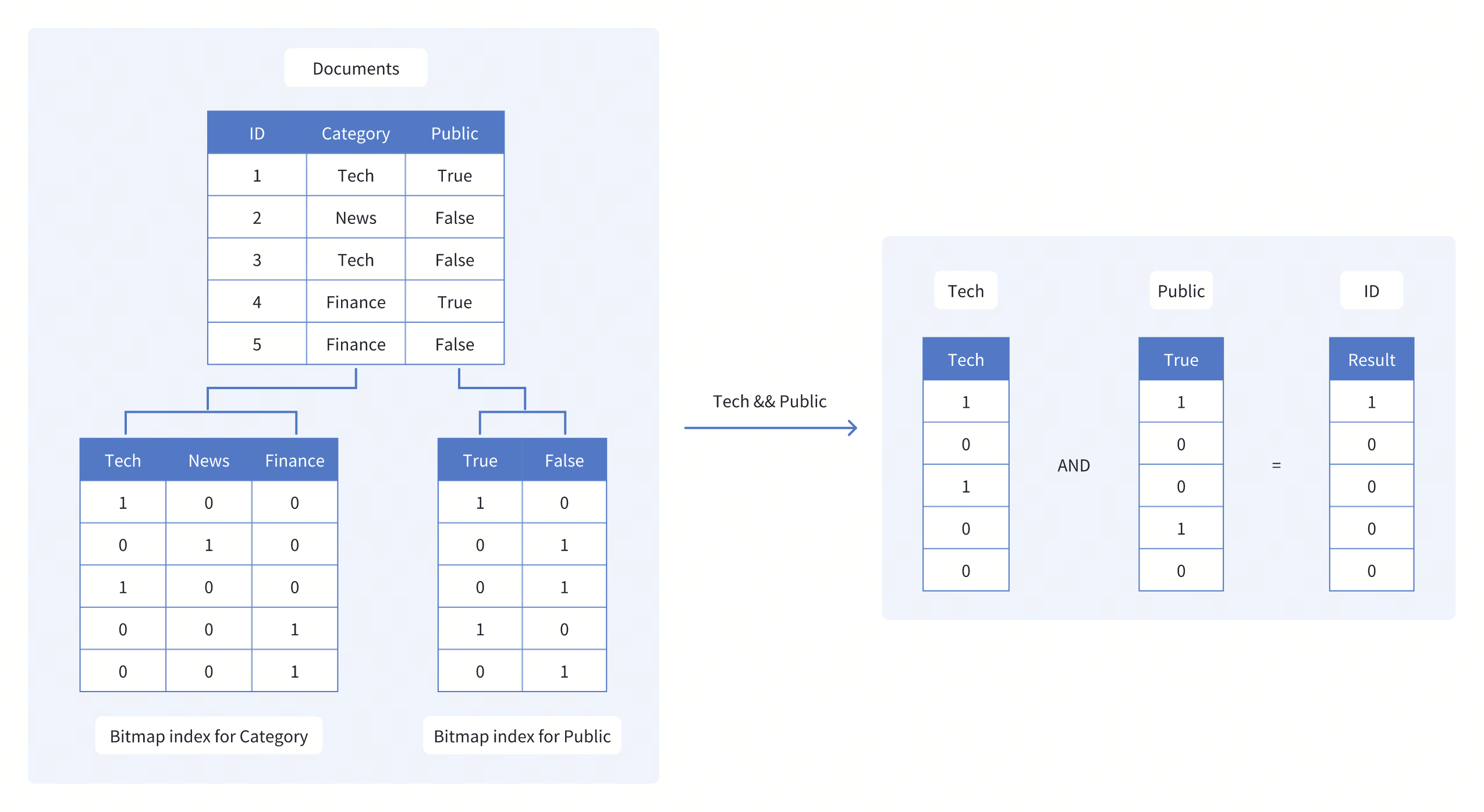
5) GiST / GIN / SP-GiST (PostgreSQL)
Просто знать, что они есть:
- GiST — геоданные, сложные типы, KNN.
- GIN — полнотекстовый поиск, массивы.
- SP-GiST — префиксы, IP, нерегулярные структуры.
Финальные мысли
Индексы — это мощный инструмент, но не магия. Неправильно поставленный индекс может замедлить систему сильнее, чем отсутствие индекса.
Если интересна тема глубже, можно посмотреть:
- видео от разраба из Озона про выбор индексов
- канал ораклиста про планы запросов