Куратор раздела
Data Lakehouse
Data Lakehouse — это архитектура, которая объединяет преимущества Data Lake и DWH. Проще говоря: хранение как в озере (дёшево и гибко), а удобство работы — как в хранилище (SQL, транзакции, качество).
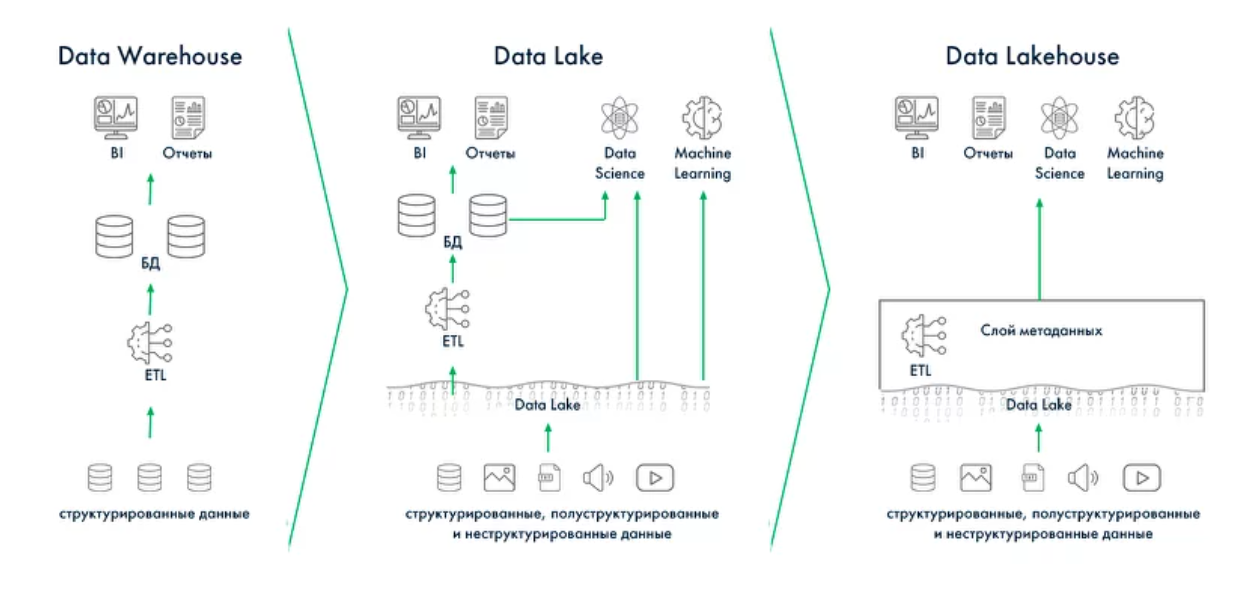
Почему появился Lakehouse
Классический DWH даёт:
- строгую структуру,
- качество и контроль,
- надёжную аналитику.
Но у него есть минусы:
- дорогая поддержка,
- жёсткие схемы,
- плохо работает с сырыми и разнородными данными.
Data Lake решил проблему гибкости:
- можно хранить любые форматы,
- дешевое масштабирование,
- быстрое добавление источников.
Но у озера не хватало:
- транзакционности (ACID),
- контроля качества,
- нормального SQL-доступа.
Lakehouse — это попытка объединить лучшее из двух подходов.
Ключевая идея Lakehouse
Данные хранятся в озере, но управляются как таблицы DWH.
Это стало возможным благодаря open table formats:
- Apache Iceberg
- Delta Lake
- Apache Hudi
Эти форматы дают:
- ACID-транзакции
- историю изменений (time travel)
- эволюцию схемы
- нормальную производительность запросов
Из чего состоит Lakehouse
1) Storage Layer (Хранилище)
Обычно это объектные или распределённые хранилища:
- Amazon S3 / S3-compatible
- Azure Data Lake Storage
- Google Cloud Storage
- HDFS
Там лежат все типы данных: таблицы, логи, события, изображения, JSON и т.д.
2) Table Format Layer (табличные форматы)
Этот слой превращает «файлы» в «таблицы». Он отвечает за:
- транзакции
- снапшоты
- партиционирование
- метаданные
3) Catalog Layer (каталог)
Хранит информацию о таблицах и их версиях:
- Hive Metastore
- AWS Glue
- Project Nessie
Это точка входа для всех движков.
4) Compute Layer (вычисления)
Lakehouse работает с любыми движками:
- Batch: Spark, Trino, Presto
- Streaming: Flink, Spark Streaming
- ML: PyTorch, TensorFlow, MLflow
5) BI и аналитика
BI-инструменты могут подключаться напрямую:
- Power BI
- Tableau
- Looker
- Superset
6) Управление и безопасность
Без этого в enterprise никуда:
- контроль качества
- аудит
- lineage
- разграничение доступа
Преимущества Lakehouse
- единый слой для BI и ML
- дешёвое хранение
- поддержка любых данных
- SQL + транзакции
- гибкость и масштабирование
Когда Lakehouse подходит
- много данных разного типа
- нужно совместить аналитику и ML
- есть потоковые данные
- нужны ACID и time-travel
Если данных мало и нужен только BI — классического DWH может быть достаточно.