Куратор раздела

HDFS
На многих проектах в качестве хранилища используют HDFS (Hadoop) и инструменты экосистемы hadoop. Также про это часто спрашивают на собеседованиях
Смотри видео про HDFS

➜ Ссылка на видео, если не получилось кликнуть на обложку (opens in a new tab)
Небольшая теория текстом
Hadoop Distributed File System — Это не просто хранилище данных, а скорее распределенная система хранения. Представь себе, что у тебя есть огромный объем информации – терабайты, петабайты. Хранить все это на одном компьютере просто невозможно.
HDFS решает эту проблему, разбивая данные на куски и распределяя их по множеству серверов в сети. Каждый сервер хранит только часть данных, но вместе они образуют единое, "массивное" хранилище. Это позволяет добиться невероятной эффективности: данные читаются и записываются быстрее, чем если бы они были на одном диске.
Самое крутое, что HDFS обеспечивает высокую отказоустойчивость – если один сервер выйдет из строя, данные не потеряются, потому что они дублируются на других серверах. Ещё он масштабируется – можно добавлять новые серверы по мере необходимости, чтобы хранить всё больше данных.
В общем, HDFS - это как очень умный способ хранить и обрабатывать огромные объемы информации, который используется в разных областях, от финансов до онлайн-сервисов."
Почему HDFS стал таким важным:
-
Распределяет данные по множеству серверов, то есть разбивает большие файлы на мелкие кусочки и автоматически кладет их на разные сервера.
-
Он очень надежный – отказоустойчивый. У него есть резервные копии каждого кусочка данных (кол-во копий можно настроить и кстати называется это репликацией), так что если один серер сломается, данные останутся на других.
-
Он масштабируется – можно легко добавлять новые машины, чтобы хранить ещё больше данных, без необходимости переделывать всю систему. Правда с этим могут быть некоторые нюансы, но о них позже.
-
Данные обрабатываются параллельно, что делает анализ очень быстрым.
Архитектура HDFS:
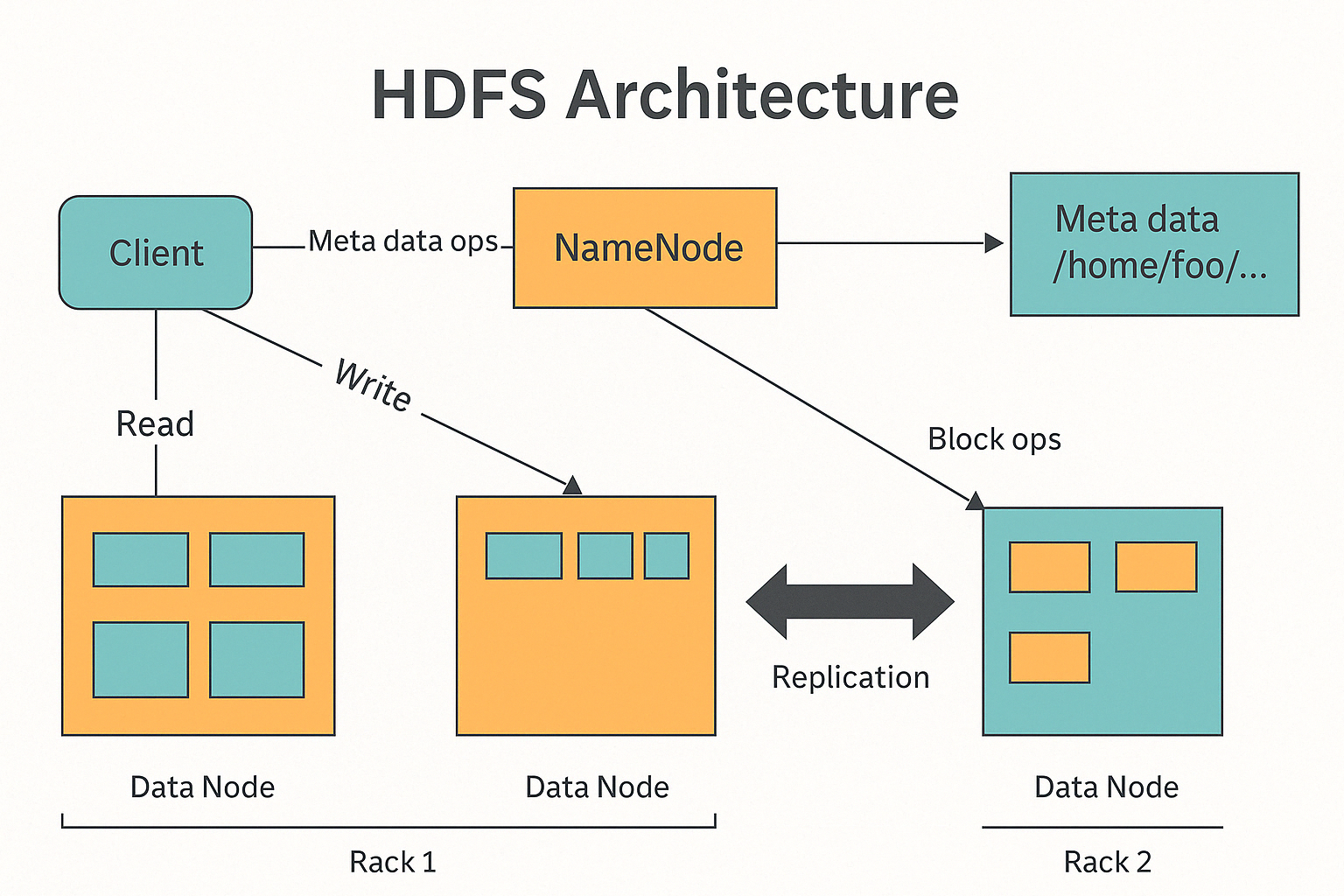
Основные компоненты системы
NameNode
NameNode – это справочник файловой системы. NameNode знает, где именно хранятся все файлы и блоки данных. Она хранит информацию о структуре HDFS, но сама не хранит данные – это делается на других узлах. Все запросы на чтение или запись начинаются с обращения к NameNode. Кстати если переполнить NameNode, то HDFS больше не сможет вмещать в себя данные.
DataNode
Это обычные сервера, на которых и хранятся сами данные. HDFS разбивает большие файлы на маленькие кусочки – блоки – и распределяет их по этим DataNode. DataNode отвечают за чтение и запись этих блоков, а также за то, чтобы данные были надежно защищены, например, делая несколько копий каждого блока."
Кстати размер блока обычно настраивают на 128Мб или на 256Мб. Но на самом деле ничего не мешает изменть эту настройку и поставить хоть 1кБ, хоть 1Гб. Оптимальный размер блока в HDFS был вычислен чисто опытным путем.
Сразу приведу пример, почему 128Мб это оптимально
Представьте таблицу размером 100Гб. Допустим это данные про землетрясения. Очень наверняка при запросе, мы захотим прочитать данные за какой-то день или об определенной локации. Т.е. мы явно будем применять фильтр. Если бы хранили одним блоком в 100Гб, то пришлось бы долго ждать, пока система прочтет целый ОГРОМНЫЙ БЛОК. Все равно, что Excel листать в поисках нужной строки.
А вот если мы разобьем на блоки, то система может считывать только конкретные блоки, которые нам нужны. Это ускорит скорость чтения в десятки-сотни раз! Ну например достаточно будет взять на чтение несколько блоков по 128Мб из 800.
Но правда если мы разобъем данные на слишком маленькие блоки, например по 1кБ, то это тоже не будет хорошо. Это уже связано с тем, как HDD диск читает данные внутри. Головка внутри диска будет очень часто менять положение в рамках сбора данных - а это только увеличит время чтения.
Поэтому решили оптимально брать размер блока в 128Мб.
Client (Клиент)
Это как ты или любое приложение, которое хочет получить доступ к данным. Клиент не передает данные напрямую, а сначала спрашивает у главного справочника – NameNode. И напрямую обменивается данными с узлами хранения — DataNode.
💻 CLI-команды HDFS
| Категория | Команда | Описание |
|---|---|---|
| Работа с файлами | hdfs dfs -ls /путь | Просмотр содержимого директории |
hdfs dfs -mkdir /путь | Создание новой директории | |
hdfs dfs -put файл /hdfs/путь | Загрузка файла в HDFS | |
hdfs dfs -get /hdfs/файл путь | Скачивание файла из HDFS | |
hdfs dfs -cat /файл | Просмотр содержимого файла | |
hdfs dfs -rm /файл | Удаление файла | |
hdfs dfs -rm -r /каталог | Рекурсивное удаление каталога | |
hdfs dfs -mv /старый /новый | Переименование или перемещение файла | |
| Права и доступ | hdfs dfs -chmod 755 /путь | Изменение прав доступа |
hdfs dfs -chown пользователь:группа /путь | Изменение владельца | |
hdfs dfs -chgrp группа /путь | Изменение группы | |
| Репликация | hdfs dfs -setrep -w 2 /файл | Установка фактора репликации |
hdfs dfs -getrep /файл | Просмотр текущего уровня репликации | |
| Инфо о системе | hdfs dfsadmin -report | Информация о состоянии DataNode |
hdfs dfs -du -h /путь | Размер директории/файла | |
hdfs dfs -df -h | Использование пространства в HDFS | |
hdfs dfs -count /путь | Количество файлов, директорий и байт |