Pet Project
Содержание страницы
Проекты
Проект №0 - Sandbox DB
Песочница для Дата Инженера ➜ Sandbox DB (opens in a new tab)
Проект №1 - HalltapeETLPipeline
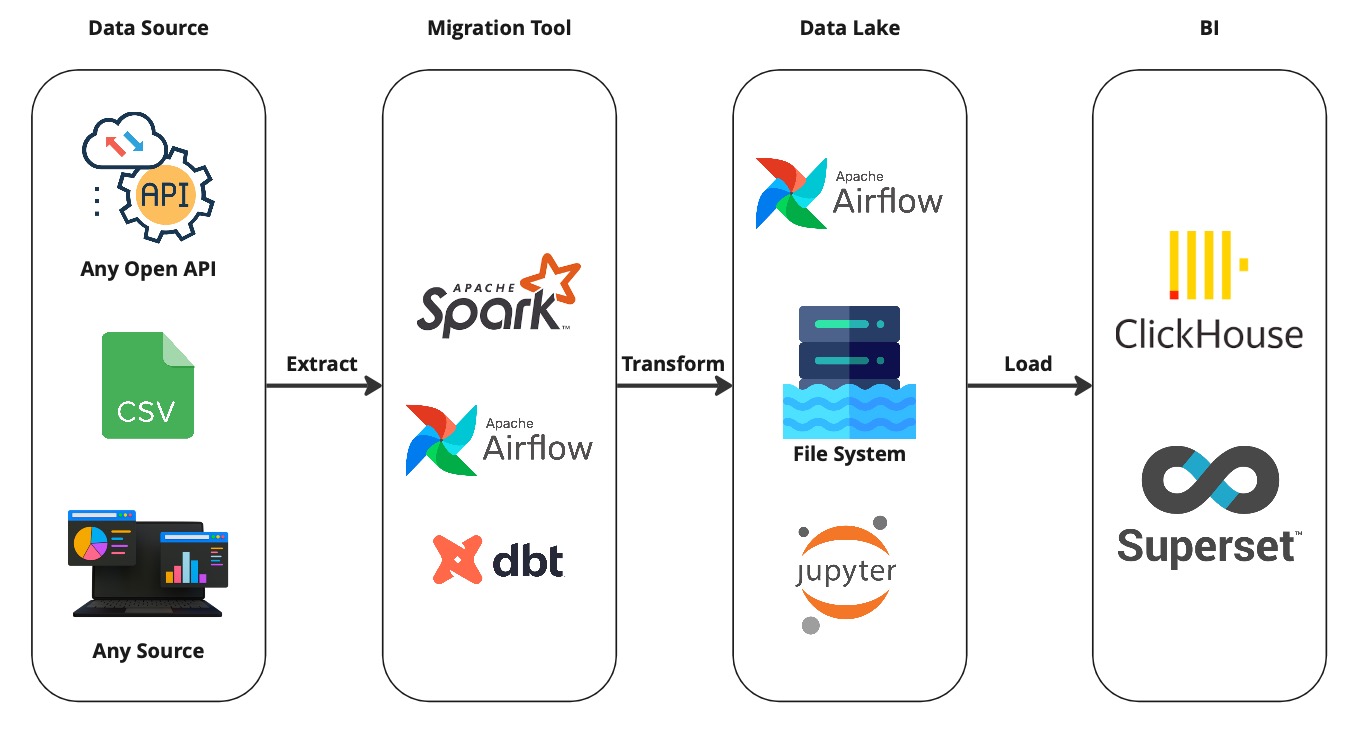
Важно! Этот проект был таким не сразу. Первые его версии содержали только Airflow, Clickhouse и Pandas под капотом. Поэтому не думайте, что я сразу был суперменом. Все добавлялось и допиливалось уже позже. Но база была та же.
Любой пет проект ты можешь собрать, как с нуля, так и взять готовый шаблон по типу моего. В проекте ниже есть минимальный набор необходимых инструментов. Твоя задача – настроить ETL процесс. Данные можно, как сгенерировать свои, так и скачать по API или с любого другого ресурса. Ограничение только твоя фантазия. Этот проект больше, как шаблон. То, как выстроить весь процесс работы с данными – твоя задача.
Вот, что там уже есть:
- Генерация синтетических данных
- Построение простой витрины данных на Spark
- Мониторинг качества данных
- dbt модель для витрины данных в Clickhouse
- dbt модель для качества данных в Clickhouse
Для сборки проекта тебе понадобятся знания Git, Docker
Собери его у себя ➜ Pet Project HalltapeETLPipeline (opens in a new tab)
Проект №2 - spacex-api-analize
По всем вопросам по данному проекту можно обращаться к Шустикову Владимиру в телеграмм канале – Инженерообязанный (opens in a new tab)
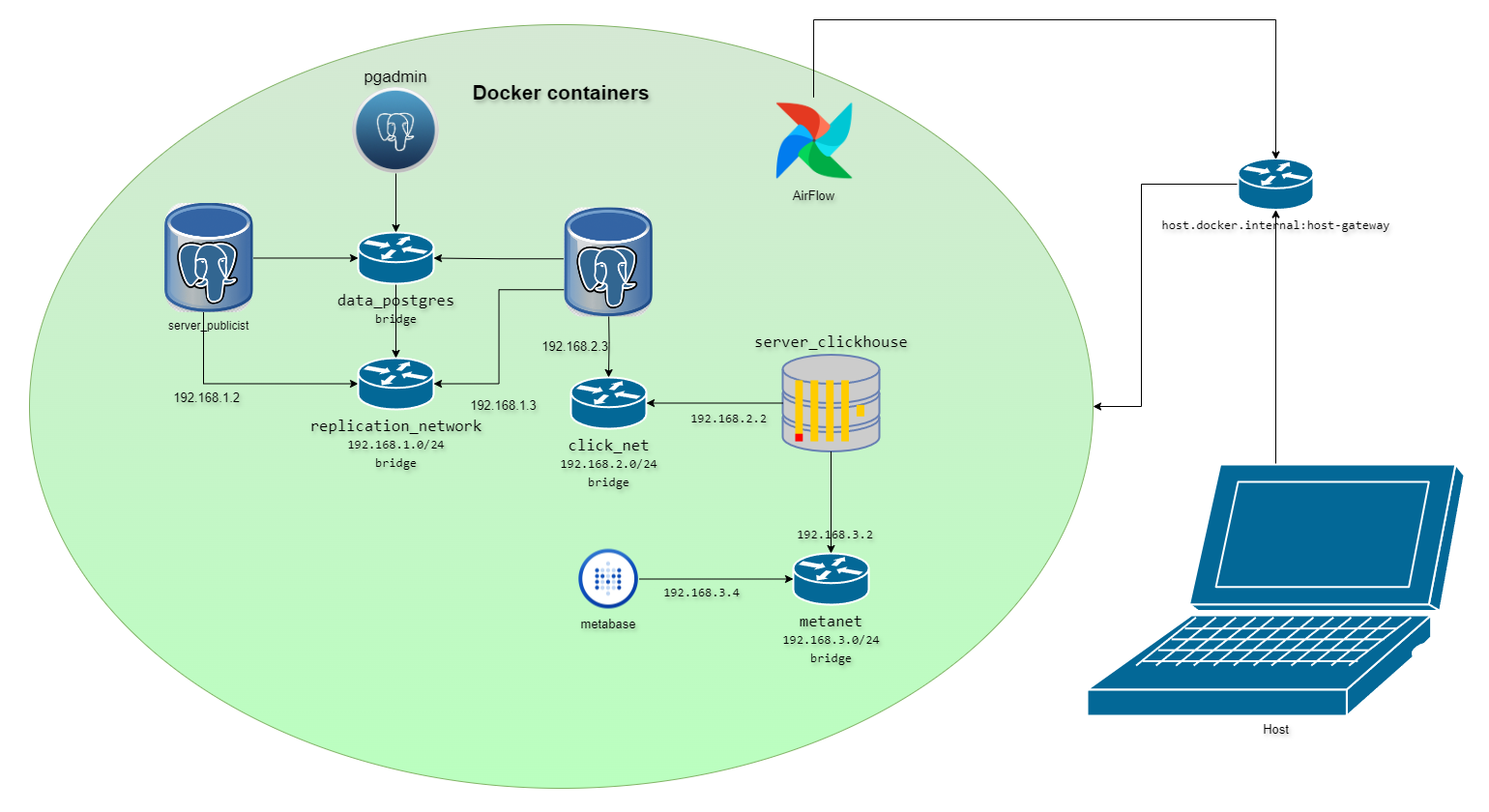
Задачами проекта является настройка ETL-процесса по загрузке данных из API в базу данных, настройка сетей и логической репликации данных, автоматизация создания аналитических запросов поверх сырых данных и визуальное представление результатов на дашборде.
Здесь вы можете получить следующие знания:
- Выгрузка данных из API на AirFlow
- Работа с ООП
- Настройка сетей, а именно IP-адресации
- Логическая репликация в PostgreSQL
- Работа с внешними источниками в Clickhouse на основе движка PostgreSQL
- Построение моделей, тестов и макросов в DBT
Для сборки проекта тебе понадобятся знания Git, Docker
Собери его у себя ➜ Обработка данных SpaceX AP (opens in a new tab)
Проект №3 - Create mart in PySpark
По всем вопросам по данному проекту можно обращаться к Шустикову Владимиру в телеграмм канале – Инженерообязанный (opens in a new tab)
Задачей данного проекта была сгенерировать сырые данные и на их основе построить несколько витрин данных. Более подробно с заданием проекта можно ознакомиться здесь (opens in a new tab).
![]()
В этом проекты вы можете получить следующие знания:
- программирования на Python
- работа с Google Disk через код
- написание кода на PySpark
Собери его у себя
Проект состоит из двух блокнотов:
Для сборки проекта тебе понадобятся стабильный интернет и Google аккаунт. Вся инструкция по запуску описана в блокнотах.
Проект №4 - От почтового сервера до Greenplum
По всем вопросам по данному проекту можно обращаться к Кузьмину Дмитрию (opens in a new tab) в телеграмм канале – Дмитрий Кузьмин. Инженерия данных (opens in a new tab)
Проект №5 - Сборка витрины на Spark
![]()
Это pet-проект на Spark, в котором нужно собрать итоговую витрину лейблов Discogs из двух больших XML-датасетов: releases и labels. На выходе должен получиться один CSV-файл с информацией по лейблам, включая случаи, когда contactinfo пустой.
Что нужно сделать
- Обработать
discogs_20260301_releases.xml.gz. - Выделить из релизов данные только за последние 2 года.
- Извлечь из релизов лейблы: название и/или
id. - Обработать
discogs_20260301_labels.xml.gz. - Выполнить
joinмеждуreleasesиlabels. - Сохранить итоговую витрину в один CSV.
Исходные данные
discogs_20260301_releases.xml.gzdiscogs_20260301_labels.xml.gz- ссылка на Discogs data dump:
https://data.discogs.com/?download=data%2F2026%2Fdiscogs_20260301_releases.xml.gz - ссылка на Discogs data dump:
https://data.discogs.com/?download=data%2F2026%2Fdiscogs_20260301_labels.xml.gz - альтернатива для быстрого прототипа: parquet-датасеты с Яндекс Диска
https://disk.yandex.ru/d/W_4f_y9RpTT-Eg
Что проверяет этот проект
- Умение читать тяжёлые XML-файлы через Spark.
- Умение переводить сырые данные в parquet.
- Работу с вложенными структурами и массивами.
- Построение витрины через
explode, фильтрацию иjoin. - Подготовку итоговой выгрузки в понятном табличном виде.
Acceptance Criteria
releasesпреобразован из XML в parquet.labelsпреобразован из XML в parquet.- Для
releasesвыделенrelease_year. - Данные отфильтрованы за последние 2 года.
- Из
releasesизвлеченыlabel_nameи/илиlabel_id. - Выполнен
joinсlabels. - Витрина включает строки с пустым
contactinfo. - Результат сохранён в один CSV-файл.
- В CSV как минимум есть
label_nameиcontactinfo. - Плюсом будут поля
id,parent_label_name,parent_label_id,profile,sublabel_names,sublabel_ids,urls,data_quality.
Порядок работы
- Сначала конвертируешь
labels.xmlв parquet. - Потом поднимаешь конвертацию
releases.xmlв parquet с партиционированием поrelease_year. - После этого собираешь витрину через Spark и сохраняешь результат в один CSV.
Пример пайплайна
Ниже лежат готовые заготовки скриптов. Они большие, поэтому убраны в раскрывающиеся блоки, и каждый можно сразу скопировать.
Скрипт: labels XML в parquet
# 400MB
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("XML to Parquet")
.master("local[8]")
.config("spark.driver.memory", "8g")
.config("spark.driver.host", "127.0.0.1")
.config("spark.driver.bindAddress", "127.0.0.1")
.config("spark.hadoop.io.native.lib.available", "false")
.getOrCreate()
)
print(f"Spark UI: {spark.sparkContext.uiWebUrl}")
INPUT_PATH = "file:///Q:/disks/M/_python_projects/spark/discogs_20260301_labels.xml"
OUTPUT_PATH = "file:///Q:/disks/M/_python_projects/spark/labels_parquet"
df = spark.read.format("xml").option("rowTag", "label").load(INPUT_PATH)
df.printSchema()
df.write.mode("overwrite").parquet(OUTPUT_PATH)Скрипт: releases XML в parquet
# fmt: off
# 60GB
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import StructType, LongType, StringType, ArrayType, StructField, IntegerType
spark = (
SparkSession.builder.appName("Releases XML to Parquet")
.master("local[8]")
.config("spark.driver.memory", "32g")
.config("spark.sql.shuffle.partitions", "32")
.config("spark.driver.host", "127.0.0.1")
.config("spark.driver.bindAddress", "127.0.0.1")
.config("spark.hadoop.io.native.lib.available", "false")
.getOrCreate()
)
INPUT_PATH = "file:///Q:/disks/M/_python_projects/spark/discogs_20260301_releases.xml"
OUTPUT_PATH = "file:///Q:/disks/M/_python_projects/spark/releases_parquet"
release_schema = StructType([
StructField("_id", LongType(), True),
StructField("released", StringType(), True),
StructField("title", StringType(), True),
StructField("country", StringType(), True),
StructField("notes", StringType(), True),
StructField("data_quality", StringType(), True),
StructField("master_id", StructType([
StructField("_VALUE", LongType(), True),
StructField("_is_main_release", StringType(), True),
]), True),
StructField("artists", StructType([
StructField("artist", ArrayType(StructType([
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("anv", StringType(), True),
StructField("join", StringType(), True),
])), True),
]), True),
StructField("labels", StructType([
StructField("label", ArrayType(StructType([
StructField("_id", LongType(), True),
StructField("_name", StringType(), True),
StructField("_catno", StringType(), True),
])), True),
]), True),
StructField("genres", StructType([
StructField("genre", ArrayType(StringType()), True),
]), True),
StructField("styles", StructType([
StructField("style", ArrayType(StringType()), True),
]), True),
StructField("formats", StructType([
StructField("format", ArrayType(StructType([
StructField("_name", StringType(), True),
StructField("_qty", IntegerType(), True),
StructField("_text", StringType(), True),
StructField("descriptions", StructType([
StructField("description", ArrayType(StringType()), True),
]), True),
])), True),
]), True),
StructField("tracklist", StructType([
StructField("track", ArrayType(StructType([
StructField("position", StringType(), True),
StructField("title", StringType(), True),
StructField("duration", StringType(), True),
])), True),
]), True),
StructField("extraartists", StructType([
StructField("artist", ArrayType(StructType([
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("anv", StringType(), True),
StructField("role", StringType(), True),
])), True),
]), True),
])
print("release_schema created.")
df = (
spark.read.format("xml")
.option("rowTag", "release")
.option("nullValue", "")
.option("mode", "PERMISSIVE")
.schema(release_schema)
.load(INPUT_PATH)
)
print("df created.")
df = df.withColumn(
"release_year",
F.when(
F.col("released").rlike(r"^\d{4}"),
F.substring(F.col("released"), 1, 4).cast("int")
).otherwise(F.lit(None).cast("int"))
)
print("Year normalized.")
(
df.write
.format("parquet")
.option("compression", "snappy")
.partitionBy("release_year")
.mode("overwrite")
.save(OUTPUT_PATH)
)Скрипт: сборка итоговой витрины
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, col, count, expr, concat_ws
spark = (
SparkSession.builder.appName("Releases XML to Parquet")
.master("local[8]")
.config("spark.driver.memory", "32g")
.config("spark.sql.shuffle.partitions", "32")
.config("spark.driver.host", "127.0.0.1")
.config("spark.driver.bindAddress", "127.0.0.1")
.config("spark.hadoop.io.native.lib.available", "false")
.getOrCreate()
)
print(f"Spark UI: {spark.sparkContext.uiWebUrl}")
LABELS = "datasets/labels_parquet/*.parquet"
RELEASES = "datasets/releases_parquet"
labels = spark.read.parquet(LABELS)
releases = spark.read.parquet(RELEASES).where(
""" release_year between 2024 and 2027 """
)
labels_flat = releases.withColumn(
"label_exploded", explode(col("labels.label"))
).select(
col("_id").alias("release_id"),
col("title"),
col("release_year"),
col("label_exploded._id").alias("label_id"),
col("label_exploded._name").alias("label_name"),
col("label_exploded._catno").alias("catalog_number"),
)
release_labels_flat = (
labels_flat.where(""" label_name IS NOT NULL """).select("label_name").distinct()
)
result = release_labels_flat.join(
labels, release_labels_flat.label_name == labels.name, "inner"
).drop("name")
save_to_csv = result.select(
"id",
"label_name",
"contactinfo",
"parentLabel",
"profile",
"sublabels",
"urls",
"data_quality",
)
labels_final = save_to_csv.select(
col("id"),
col("label_name"),
col("contactinfo"),
col("parentLabel._VALUE").alias("parent_label_name"),
col("parentLabel._id").alias("parent_label_id"),
col("profile"),
expr("transform(sublabels.label, x -> x._VALUE)").alias("sublabel_names"),
expr("transform(sublabels.label, x -> x._id)").alias("sublabel_ids"),
col("urls.url").alias("urls"),
col("data_quality"),
).select(
col("id"),
col("label_name"),
col("contactinfo"),
col("parent_label_name"),
col("parent_label_id"),
col("profile"),
concat_ws(" | ", col("sublabel_names")).alias("sublabel_names"),
concat_ws(" | ", col("sublabel_ids")).alias("sublabel_ids"),
concat_ws(" | ", col("urls")).alias("urls"),
col("data_quality"),
)
(
labels_final.coalesce(1)
.write.format("csv")
.options(sep=";", header=True, encoding="UTF-8", quote='"', escape='"')
.mode("overwrite")
.save("lables_info_2024_2026.csv")
)
# проверка
# labels_final.groupBy("label_name").agg(count("*").alias("total_rows")).orderBy(col("total_rows").desc()).show()На что обратить внимание
- В текущем примере
joinвыполняется поlabel_name. - Для более надёжной реализации лучше использовать
label_id = labels.id, еслиidкорректно извлекается изreleases. - Для больших объёмов данных
releasesлучше хранить parquet с партиционированием поrelease_year. - Даже если
labels.contactinfoравенNULL, запись всё равно должна попасть в итоговую витрину.
Что получится в итоге
После выполнения проекта у тебя будет полноценный mini data engineering pipeline:
- чтение сырых XML;
- преобразование в parquet;
- фильтрация по времени;
- извлечение вложенных полей;
- join со справочником;
- выгрузка витрины в CSV.
Это уже очень близко к реальной задаче дата-инженера, а не просто к учебному ноутбуку.
Проект №6 - PetProjectDataEngineer

Собери его у себя ➜ PetProjectDataEngineer (opens in a new tab)
Открытые API для проектов
- Launch Library 2 (opens in a new tab) - Запуски ракет, космические события и космические полеты с экипажем.
- SpaceX API (opens in a new tab) - Информация о компании SpaceX.
- Wikimedia (opens in a new tab) - Дампы данных о посмотрах страниц в Википедии в текстовом виде.