Немного об этой главе
Экосистема Hadoop обычно разворачивается в компаниях, которые работают с Big Data. Поэтому важно понимать не только HDFS, но и весь набор ключевых компонентов вокруг него.
Компоненты экосистемы Hadoop
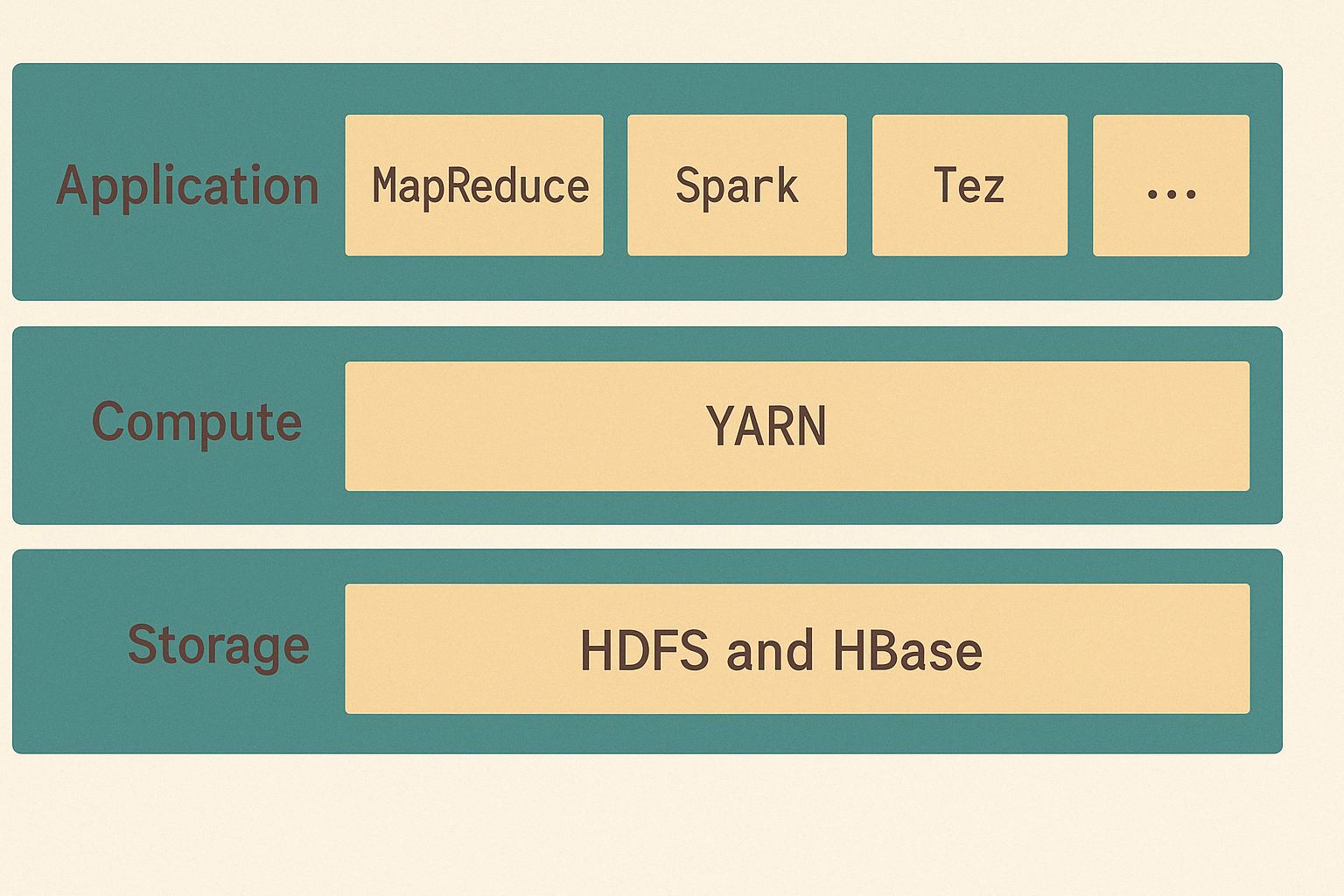
HDFS (Hadoop Distributed File System)
Распределённая файловая система для надёжного и масштабируемого хранения больших массивов данных на кластере стандартных серверов.
YARN (Yet Another Resource Negotiator)
Слой управления ресурсами и планированием задач. Он распределяет вычислительные ресурсы между приложениями: MapReduce, Spark, Tez и другими.
MapReduce и Spark
Движки для распределённой обработки данных:
- MapReduce — классическая модель обработки больших данных.
- Spark — более современный, быстрый и гибкий фреймворк для распределённых вычислений в памяти.
Дополнительные инструменты
- Hive — SQL-подобный интерфейс для анализа данных в Hadoop.
- Pig — язык потоков данных, простой в использовании для анализа.
- HBase — распределённая колонко-ориентированная база данных.
- Oozie — планировщик рабочих процессов (workflow scheduler).
- ZooKeeper — служба координации и управления распределёнными приложениями.
MapReduce
Зачем нужен MapReduce?
Когда объёмы данных стали измеряться терабайтами и петабайтами, классические подходы перестали справляться. MapReduce появился как ответ на эту проблему и стал основой распределённых вычислений в экосистеме Hadoop.
Как работает MapReduce?
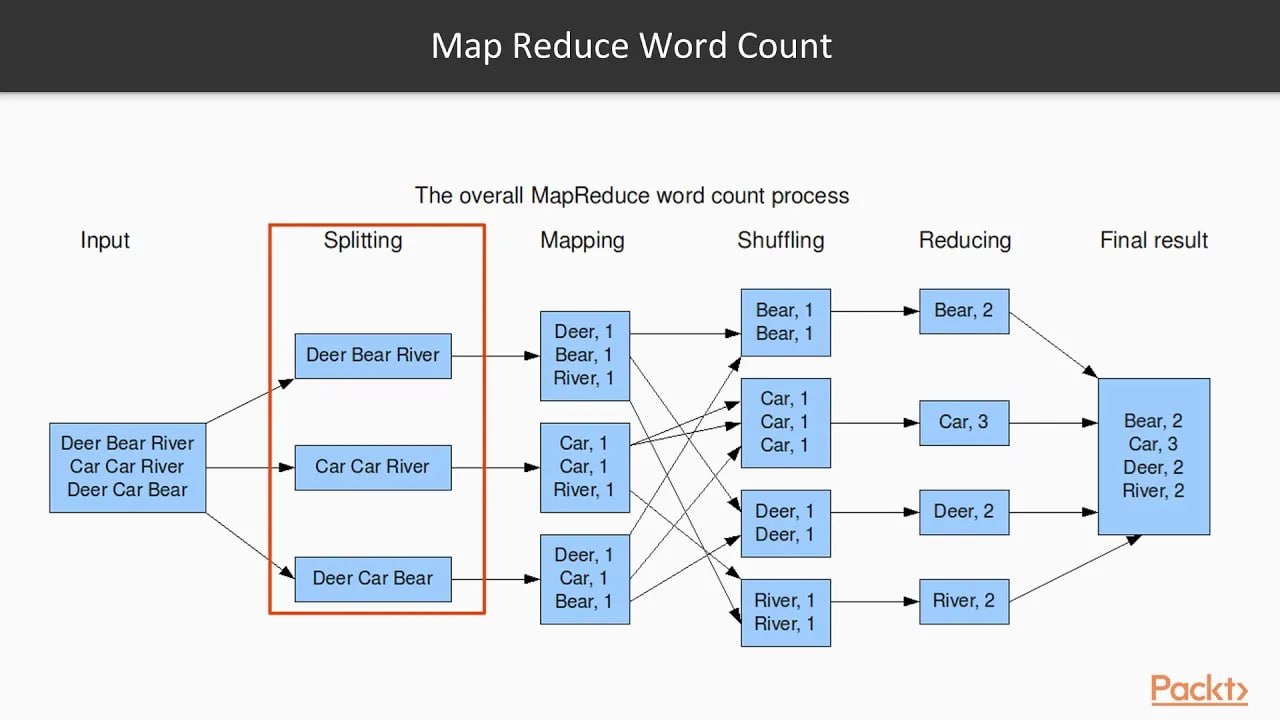
MapReduce делит большую задачу на множество мелких и обрабатывает их параллельно на разных узлах кластера.
Этапы обработки:
- Input
На вход подаётся большой массив данных: текст, логи, последовательности ДНК и т.д. - Splitting
Данные делятся на фрагменты, которые обрабатываются независимо. - Mapping
Каждый фрагмент проходит через функциюmap, которая превращает данные в пары «ключ — значение». - Shuffling
Все одинаковые ключи группируются. - Reducing
К каждой группе применяется функцияreduce, которая агрегирует значения. - Result
Формируется итоговый результат.
Что было до YARN?
В Hadoop 1.x обработка данных была жёстко связана с управлением ресурсами. В центре находился JobTracker, а на каждом узле работал агент TaskTracker.
JobTracker принимал задания, делил их на задачи, распределял по узлам, контролировал выполнение и восстанавливал упавшие задачи. Он одновременно был координатором и диспетчером ресурсов, что приводило к перегрузке на больших кластерах.
TaskTracker запускался на каждом рабочем узле и исполнял полученные задачи, периодически отправляя статус. При этом слоты для map и reduce были фиксированными, и если задачи одного типа отсутствовали, часть ресурсов простаивала.
Масштабируемость была ограничена: JobTracker держал в памяти информацию обо всех задачах и заданиях. При большом количестве работ он превращался в узкое место и мог выйти из строя. Поскольку это была единственная точка отказа, сбой останавливал весь кластер.
Что такое YARN?
Чтобы снять эти ограничения, в Hadoop 2.x появилась новая система управления ресурсами — YARN (Yet Another Resource Negotiator). Она отделила управление ресурсами от логики выполнения приложений и сделала платформу более гибкой, устойчивой и расширяемой.
С YARN Hadoop перестал быть привязан только к MapReduce. На одном кластере могут параллельно работать Spark, Hive, Tez, Flink и другие фреймворки. Это превратило Hadoop в универсальную платформу для обработки больших данных.
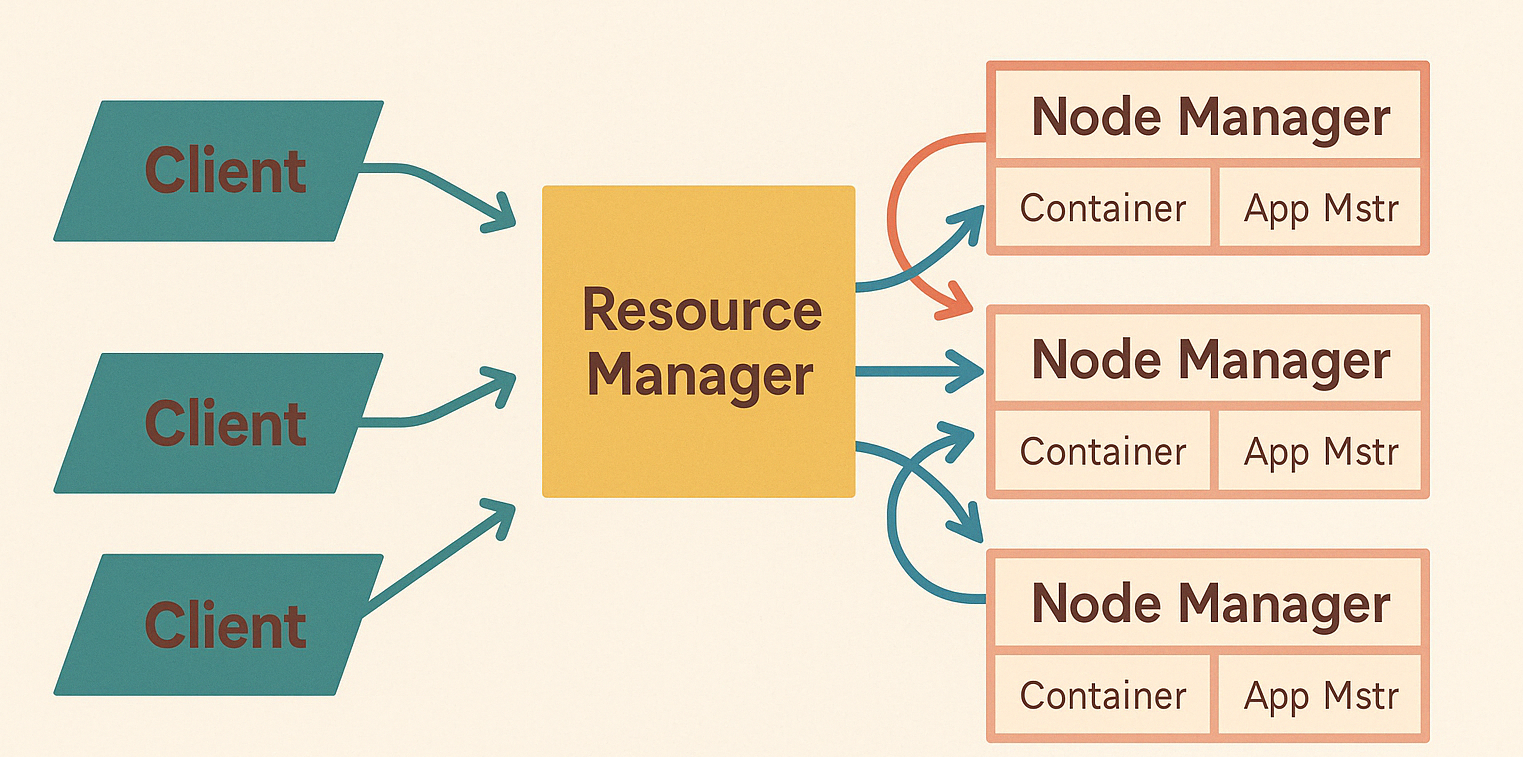
Архитектура YARN в Hadoop 2.x
Для решения проблем предыдущей версии в Hadoop 2.x была представлена новая архитектура — YARN (Yet Another Resource Negotiator). Она стала ключевым компонентом, кардинально изменившим подход к управлению ресурсами в распределённой среде.
Ключевая идея YARN — разделить управление ресурсами и выполнение приложений, чтобы система стала гибче, масштабируемее и пригодной для разных типов вычислений, а не только для MapReduce.
Основные компоненты YARN:
-
ResourceManager
Центральный управляющий компонент, выполняющий роль глобального диспетчера ресурсов кластера. Он принимает заявки на ресурсы от приложений, распределяет ресурсы между ними и следит за состоянием узлов. При этом ResourceManager не управляет задачами напрямую. -
ApplicationMaster
Это уникальный процесс, который запускается отдельно для каждого приложения (например, Spark, Hive, MapReduce и др.). Он отвечает за:- организацию выполнения приложения,
- переговоры с ResourceManager по поводу выделения ресурсов,
- управление задачами внутри приложения.
Такой подход позволяет запускать разные приложения параллельно, независимо друг от друга.
-
NodeManager
Агент, работающий на каждом узле кластера. Он:- отслеживает локальные ресурсы (CPU, память, диск и т.д.),
- отправляет отчёты ResourceManager'у,
- запускает контейнеры (containers) — изолированные среды выполнения задач.
-
Container
Это изолированная среда, в которой выполняются задачи приложения — будь то MapReduce, Spark, или любой другой фреймворк. Контейнеры запускаются и управляются NodeManager'ом.
Зачем это всё?
Благодаря этой архитектуре, YARN предоставляет универсальный и расширяемый слой управления ресурсами, который может обслуживать не только MapReduce-приложения, но и любые другие распределённые фреймворки. Это позволило:
- эффективно использовать ресурсы кластера,
- масштабировать системы до тысяч узлов и миллионов задач,
- запускать разнообразные типы вычислений — от пакетной до потоковой обработки и ML-задач.
Результат
Благодаря YARN, Hadoop превратился из специализированной MapReduce-платформы в универсальную систему обработки больших данных, поддерживающую:
- Spark и другие in-memory вычисления,
- потоковую обработку(spark streaming),
- SQL-запросы и интерактивные аналитические задачи (Hive, Presto),
- интеграцию с ML-фреймворками.