Apache Spark: Архитектура
Что такое Spark
Apache Spark — это платформа для распределённой обработки данных в памяти. Подходит для batch и streaming, поддерживает SQL, ML и графовые вычисления.
Ключевые идеи
- DAG-модель вычислений — задачи строятся как граф зависимостей.
- Ленивая исполнение — трансформации не выполняются до
action. - Параллельность — данные делятся на партиции и обрабатываются на узлах.
- Кэширование — данные можно держать в памяти для ускорения повторных вычислений.
- Единый API — работает с
RDD,DataFrame,Dataset.
RDD простыми словами
RDD (Resilient Distributed Dataset) — распределённая неизменяемая коллекция.
Основные свойства:
- Неизменяемость — каждая операция создаёт новый RDD.
- Fault tolerance — если часть данных потерялась, Spark пересчитает её.
- Transformations —
map,filter,join(ленивые). - Actions —
count,collect,save(запускают вычисления). - Partitions — набор блоков, которые обрабатываются параллельно.
- Cache — можно держать результат в памяти или на диске.
Архитектура Spark
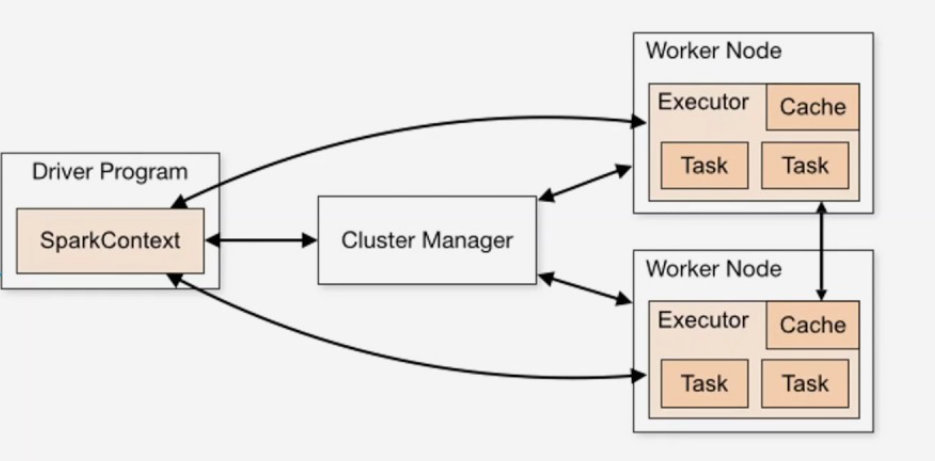
Компоненты
- Driver — главный процесс. Строит DAG, планирует задачи, собирает результат.
- SparkContext — точка входа в кластер.
- Cluster Manager — управляет ресурсами (Standalone, YARN, Kubernetes, Mesos).
- Worker — узел кластера, где запускаются вычисления.
- Executor — процесс на worker, исполняет задачи и хранит кэш.
- Task — минимальная единица работы.
Как выполняется программа
- Код запускается на Driver.
- Создаётся
SparkContext. - Строится DAG из transformations.
- DAG делится на stages и tasks.
- Cluster Manager выделяет ресурсы.
- Executors выполняют задачи.
- Результат возвращается Driver.
Экосистема Spark
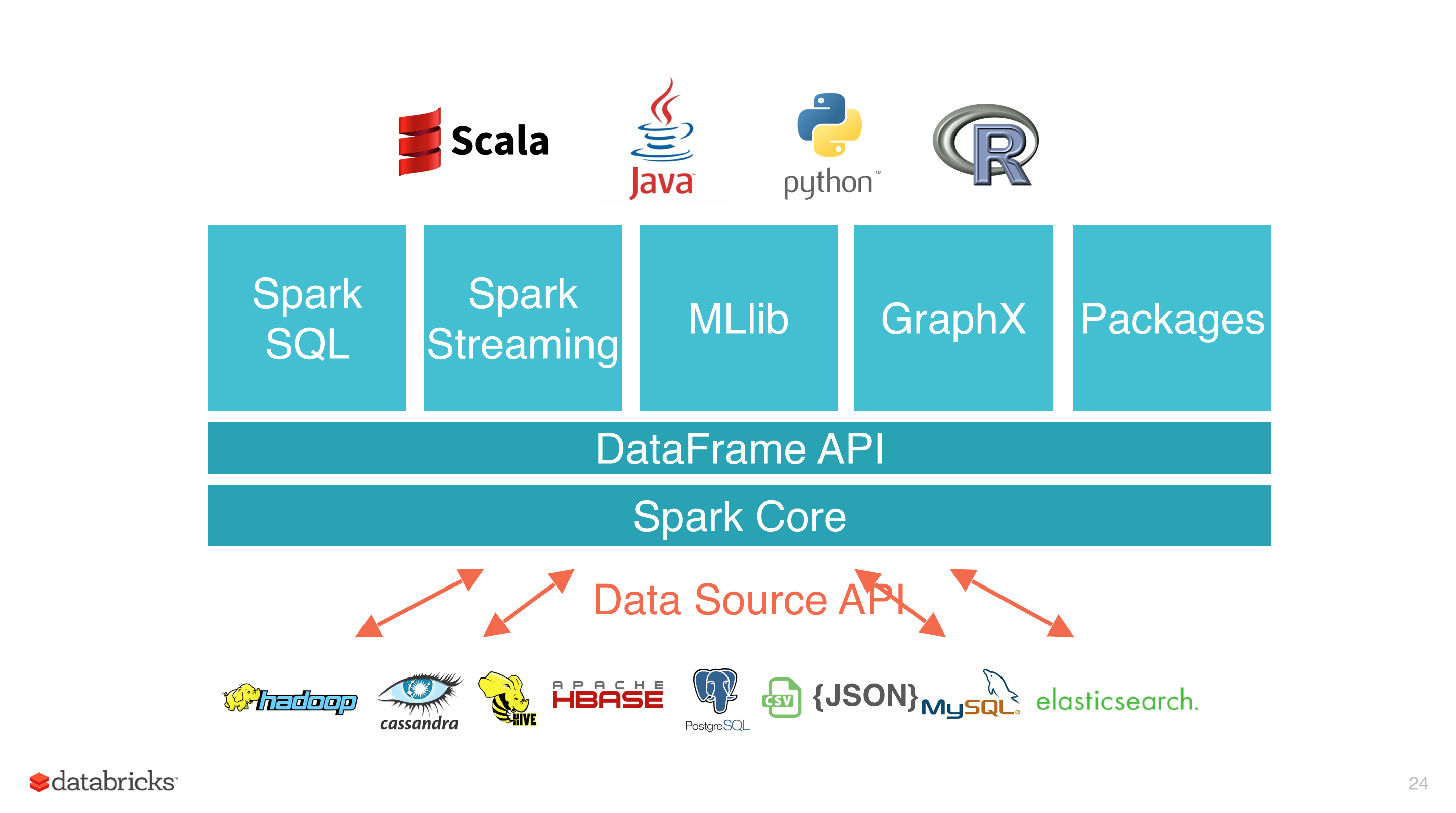
Уровни
1) Spark Core
Базовый слой:
- планирование
- управление памятью
- fault tolerance
- RDD
2) DataFrame API
Табличная абстракция поверх RDD:
- SQL-подобные запросы
- оптимизация через Catalyst
- удобное подключение источников
3) Библиотеки
| Модуль | Что делает |
|---|---|
| Spark SQL | SQL-запросы и таблицы |
| Spark Streaming | потоковые данные |
| MLlib | машинное обучение |
| GraphX | графовые вычисления |
| Packages | сторонние расширения |
4) Data Source API
Подключения к источникам:
- HDFS, Hive, HBase
- PostgreSQL, MySQL
- CSV, JSON, Parquet
- Elasticsearch и другие
Spark vs Hadoop MapReduce
MapReduce — это модель, где каждый шаг пишет результаты на диск.
Spark держит данные в памяти и строит DAG, что даёт выигрыш в скорости.
Коротко:
- MapReduce: проще концептуально, но медленнее из-за диска.
- Spark: быстрее, гибче, поддерживает batch/streaming/ML.
Если нужно много итераций (ML, сложные пайплайны) — Spark почти всегда выигрывает.
Пример DAG и Stages
Допустим, есть такой код:
read → filter → map- затем
groupBy - затем
count
Как это выглядит в Spark:
- Stage 1:
read → filter → map(узкие трансформации, без shuffle) - Stage 2:
groupBy(широкая трансформация, появляется shuffle) - Action:
countзапускает выполнение
Главная идея:
- Stage заканчивается там, где нужен shuffle.
Все операции до него выполняются вместе.